I would like calculate the loss in the following form:
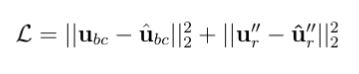
where u_bc and \hat{u}_bc are the predicted and exact values of x_1, u’‘_r and \hat{u}’'_r are the predicted and exact second derivatives of the output from x_2. x_1 and x_2 are different samples.
I am trying to implement in the following way:
# forward pass to calculate the first loss component
u_bc_pred = self.forward(self.X_u)
loss_bcs = self.loss_fnc(u_bc_pred, self.Y_u)
# the second loss component involves the second derivative of output
u_r_pred = self.forward(self.X_r)
u_x = torch.autograd.grad(u_r_pred, self.X_r, torch.ones_like(u_r_pred), retain_graph=True, create_graph=True)[0] / self.sigma_x
u_xx = torch.autograd.grad(u_x, self.X_r, torch.ones_like(u_x), retain_graph=True, create_graph=False)[0] / self.sigma_x
loss_res = self.loss_fnc(u_xx, self.Y_r)
# Total loss
loss = loss_res + loss_bcs
self.loss_log.append(loss.data)
# backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
It does not seem that my code is decreasing u_xx loss. Is there anything wrong with the way I write the second loss term involving solution gradients?
Can someone please help take a look?
Thanks a lot!