Hello, I am new in pytorch and machine learning.
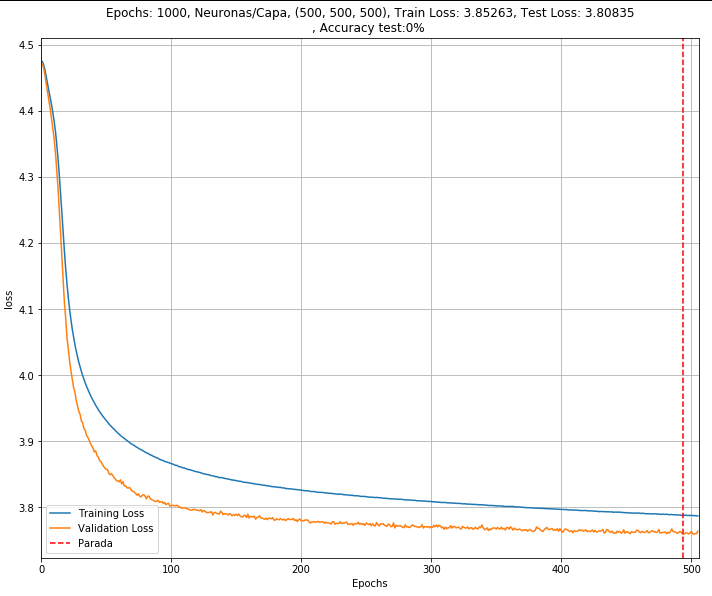
Training and validatin my dataset, I obtain loss between 4 and 3.5 per epoch.
I am using Cross Entropy Loss function.
I am calculating the mean of the epochs in the next way:
train.model()
for batch, (data, target) in enumerate(train_loader, 1):
optimizer.zero_grad()
if CUDA:
data = data.cuda()
target = target.cuda()
output = model(data)
target = torch.argmax(target,1)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
pred = torch.max(output, 1)[1]
correct_train += pred.eq(target).sum()
model.eval()
for data, target in val_loader:
if CUDA:
data = data.cuda()
target = target.cuda()
output = model(data)
target = torch.argmax(target,1)
loss = criterion(output, target)
valid_losses.append(loss.item())
pred = torch.max(output, 1)[1]
correct_val += pred.eq(target).sum()
train_loss = np.average(train_losses)
valid_loss = np.average(valid_losses)
Most of examples I had seen have losses closely to 0.
I am not sure if I my model is working correctly.
Maybe I should do:
train_loss = train_losses/len(trainLoader.dataset)
valid_loss = valid_loss/len(valLoader.dataset)
I attach an image of a train with 1000 epochs but I stopped in 505 because it was improving very slow.
I think the difference with validation loss and training loss is because there is dropout in the training.