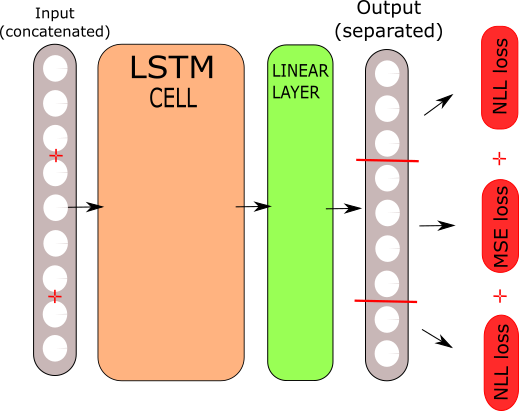
Sure :
class musicLSTM(nn.Module):
def __init__(self,input_size,output_size,hidden_size,deepness):
super().__init__()
self.deepness = deepness
self.input_size = input_size
self.output_size = output_size
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size,num_layers = deepness, batch_first = True)
self.output_layer = nn.Linear(hidden_size,output_size)
self.tanh = nn.Tanh()
self.softmax = nn.LogSoftmax(dim = 2)
def forward(self, notes, timing, harmony, hidden = None):
if hidden == None:
hidden = (torch.zeros(self.deepness,1,self.hidden_size),torch.zeros(self.deepness,1,self.hidden_size))
out, hidden = self.lstm(input,hidden)
out = self.tanh(out)
out = self.output_layer(out)
out = self.softmax(out)
else:
out, hidden = self.lstm(input,hidden)
out = self.tanh(out)
out = self.output_layer(out)
out = self.softmax(out)
return out, hidden
and the training is done with this function :
def train_rnn(model,notes,utils,chords):
start = time.time()
criterion = nn.NLLLoss()
timing_criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())
n_iters = 1000
print_every = 1
plot_every = 2
all_losses = []
total_loss = 0
for iter in range(1,n_iters+1):
optimizer.zero_grad()
loss = 0
output, hidden = model(notes, timing, harmony)
for i in range(5):
ln = criterion(output[0][i][0:130].unsqueeze(0), targetTensor(notes[0][i+1][0:130]))
lt = timing_criterion(output[0][i][130:135], timing[0][i+1])
lh = criterion(output[0][i][135:246].unsqueeze(0), targetTensor(harmony[0][i+1][0:111]))
loss += ln + lt + lh
loss.backward()
optimizer.step()
total_loss += loss.item() / notes.size(1)
if iter % print_every == 0:
print('%s (%d %d%%) %.2f' % (time_since(start), iter, iter / n_iters * 100, loss))
if iter % plot_every == 0:
all_losses.append(total_loss / plot_every)
total_loss = 0
plt.figure()
plt.plot(all_losses)
Defined that way, the training actually only happens on the first 5 notes of the song defined by notes,timing and harmony. Notes has the dimension (1, melody_length, 130), timing (1,melody_length, 5) and harmony (1, melody_length, 111). 130 and 111 being the possible pitches and chords available.