@ptrblck Thank you for your quick reply!
I used three nodes to do the experiment of distributed training.
#!/usr/bin/env python
import argparse
import os
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
from math import ceil
from random import Random
from torch.multiprocessing import Process
from torch.autograd import Variable
from torchvision import datasets, transforms
# from torchvision import models
from models import resnet
import time
from multiprocessing import Pool
import multiprocessing
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad /= size
def test(model):
correct_sum = 0
model.eval()
with torch.no_grad():
for batch_idx,(images,labels) in enumerate(testloader):
images, labels = images.to(device),labels.to(device)
output = model(images)
pred = output.argmax(dim=1, keepdim=True)
pred = pred.to(device)
correct = pred.eq(labels.view_as(pred)).sum().item()
correct_sum += correct
print("Acc:{}".format(correct_sum/len(testloader.dataset)))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--rank', type=int)
parser.add_argument('--world_size', type=int)
parser.add_argument('--batch_size', type=int, default=256)
parser.add_argument('--epoch', type=int, default=100)
parser.add_argument('--lr', type=float, default=0.1)
args = parser.parse_args()
multiprocessing.set_start_method("spawn")
os.environ["MASTER_ADDR"] = "master_ip"
os.environ["MASTER_PORT"] = "master_port"
dist.init_process_group('nccl',rank=args.rank, world_size=args.world_size)
print("init end...")
cudnn.benchmark = True
torch.manual_seed(1000)
torch.cuda.manual_seed(2000)
model = resnet.ResNet18()
device = torch.device(f"cuda:{0}" if torch.cuda.is_available() else "cpu")
model.to(device)
print("model end...")
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), args.lr, momentum=0.9, weight_decay=1e-4)
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train)
sampler = torch.utils.data.DistributedSampler(trainset,num_replicas=args.world_size,rank=args.rank)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=args.batch_size, shuffle=(sampler is None), sampler=sampler, num_workers=2)
testset = datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(
testset, batch_size=args.batch_size, shuffle=True, num_workers=2)
for epoch in range(args.epoch):
begin_time = time.time()
print('epoch', str(epoch))
model.train()
loss_sum = 0
time_sum = 0
for batch_idx,(images,labels) in enumerate(trainloader):
torch.cuda.synchronize()
batch_1 = time.time()
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(images)
loss = criterion(output,labels)
loss_sum += loss.item()
loss.backward()
average_gradients(model)
optimizer.step()
torch.cuda.synchronize()
batch_2 = time.time()
time_sum += (batch_2 - batch_1)
end_time = time.time()
print(f"time_sum:{time_sum}")
print(f"end_time-begin_time:{end_time-begin_time}")
test(model)
time.sleep(2)
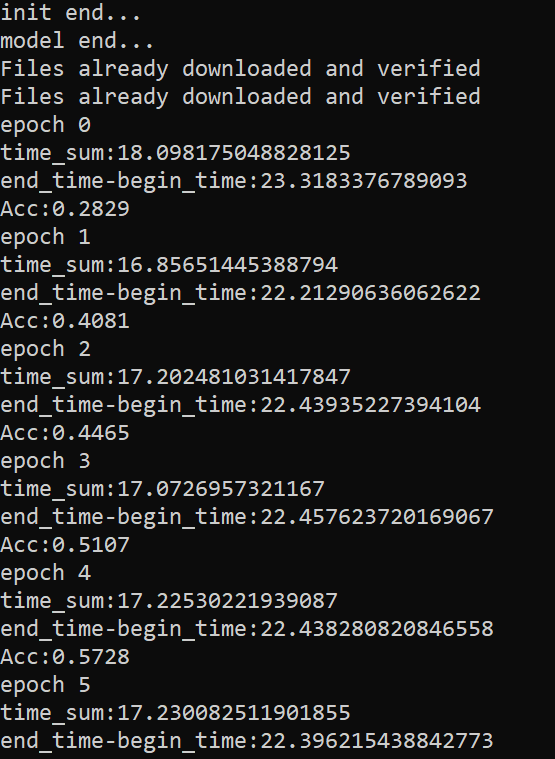
The experimental results are as follows:
node1: python3 main.py --rank 0 --world_size 3
node2: python3 main.py --rank 1 --world_size 3
node3: python3 main.py --rank 2 --world_size 3
If I delete the multiprocessing.set_start_method,the time_sum and (end_time-begin_time) are similar.
Looking forward to your reply.