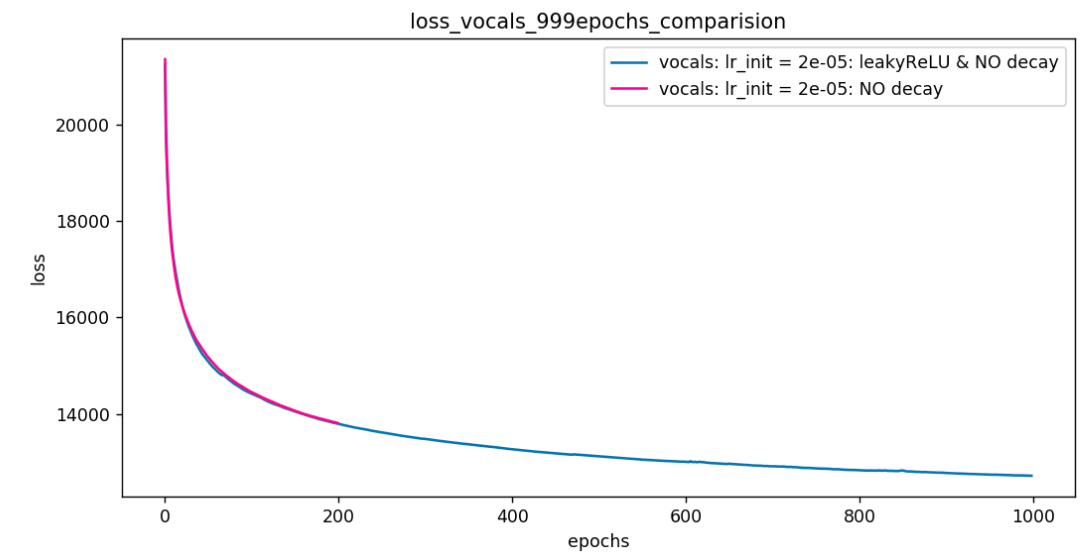
I trained on longer epochs and I got below results. The network doesnot find any loss plateau in Setup-1; but the time consumed to run so many epochs takes lots of time.
I ran 200 and 999 epochs and the results are in below graphs. 999 epochs took me 7 days on Quadro P4000.
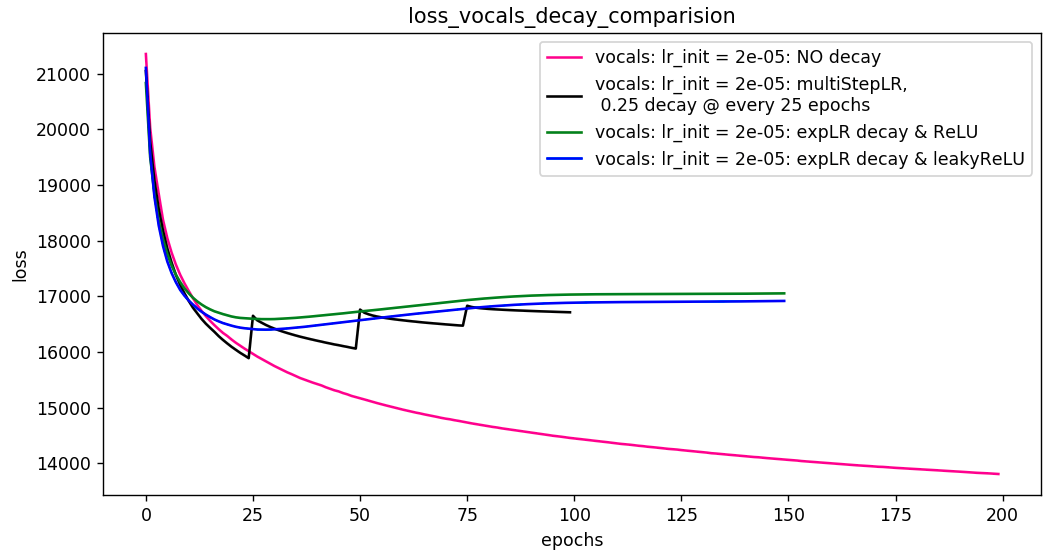
In pursuit of faster convergence, I am doing a learning rate decay.
In the processof this, I am confused by the behaviour of lr_scheduler on Adam optimizer. I’m curious if there is any implementation fault with lr_scheduler for Adam. Should optim.Adam allow lr_scheduler?