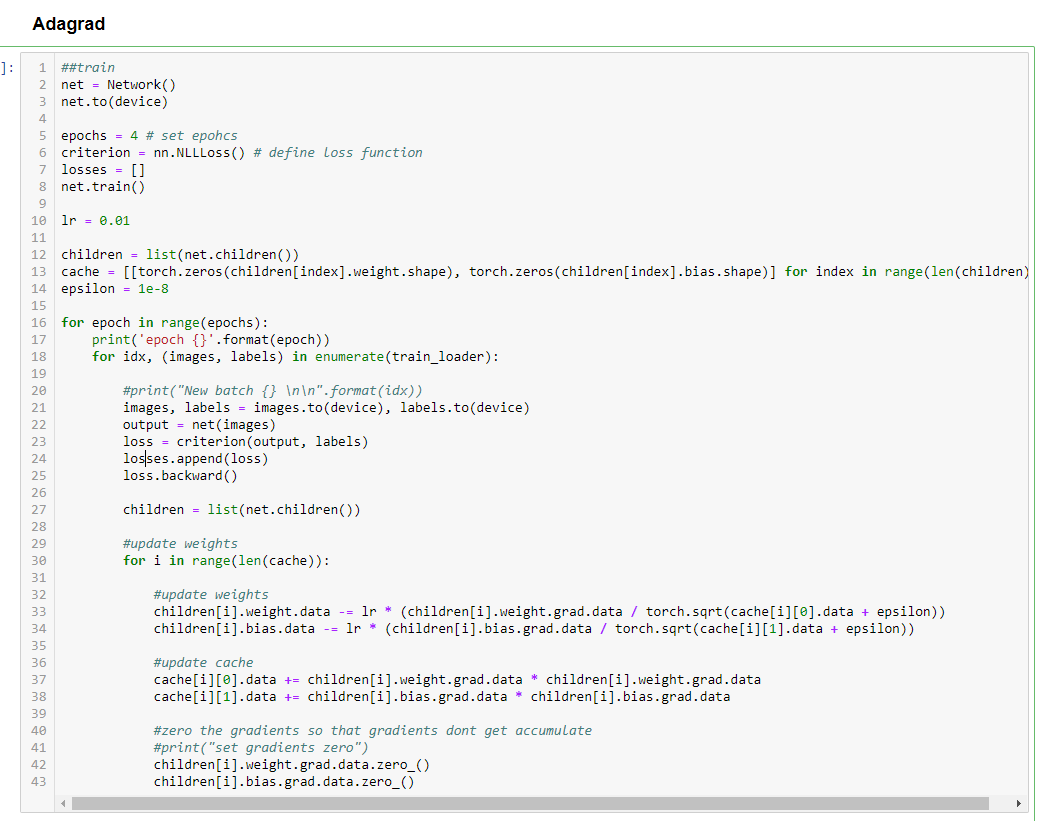
Hi. I am new to Pytorch and trying to implement various Optimizer algorithms using same. While implementing Adagrad, loss function does not converge as expected. I tried to see gradients of layers on different batches and they start to become zero very early during training. I am not able to figure out the reason for network to not converge. Is there a bug in my implementation? Can you please point me in the right direction?
I have included the picture of implementation