I would like to train an ensemble of same network architectures. Currently, I’m defining it this way.
def make_net(network_specs):
# return nn.Module
class Ensemble(nn.Module):
def __init__(self, network_specs, ensemble_size):
super().__init__()
self.model = nn.ModuleList([make_net(network_specs) for _ in range(ensemble_size)])
def forward(self, x):
return torch.stack([self.model[i](x[i]) for i in range(ensemble_size)])
However, backprop of the stack operator doesn’t seem to be parallelized (in the same GPU). The GPU utilization is very low, around 15%.
Thinking that dynamic graph might be the cause (similar thread here), I’ve recently tried using @torch.jit. The performance still doesn’t improve.
What am I doing wrong here? How can I improve the performance of my ensemble model?
All the opreations that run on the GPU are asynchronous. So if the GPU usage is very low, it’s most likely because your networks are not big enough to use all the GPU.
If your network is big enough you can try making bigger batches and check CPU and Disk usage maybe you are doing some data manipulation inside of train loop so its bottleneck.
And if you dont move big enough piece of data into .cuda() before training it also can be bottleneck and cpu usage should be pretty high.
If the network is small, we would expect the GPU utilization to get higher when we increase the ensemble size. However, the GPU utilization doesn’t increase when we scale the ensemble size. The total run time increases almost linearly with respect to the ensemble size.
Note that this is a reinforcement learning task (on simple environments), so data processing/transfer is not a bottleneck.
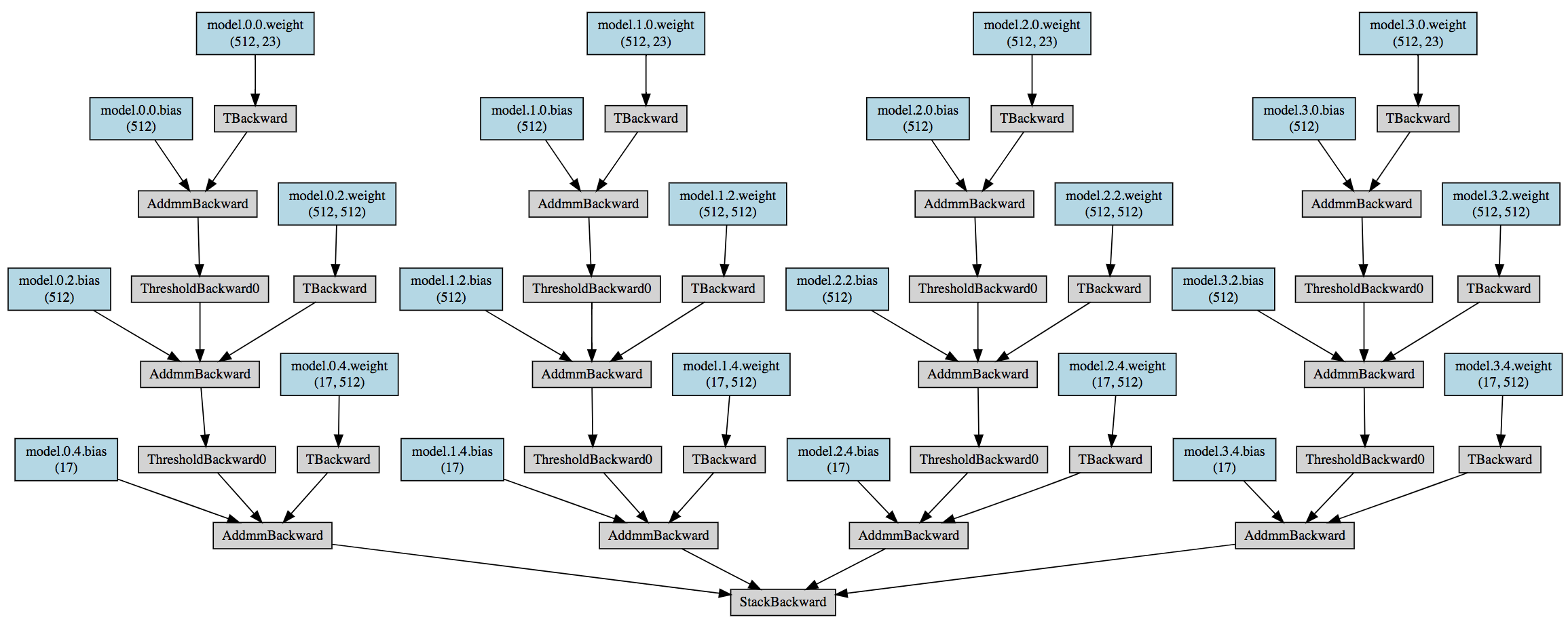
Here is the visualization of my network when the ensemble size is 4.
The thing with GPUs is that they are very good at doing one very parrallel task but not many small parrallel tasks
You can use nvidia visual profiler nvvp if you want to look more in details how your code runs on the gpu. But you’re most certainly going to have “low core usage” if you have small tasks.
hey Alban, is it also the same for a single GPU? Let’s say that I have a for loop over the enseble elements each of them doing f:x->y. Are they going to be run asynchronous even if they run on the same gpu?