Quick warning: pretty new to pytorch and pytorch-lightning frameworks
I have a set of GPS-positions and want to train a recurrent neural network to predict the next position given a previous sequence of positions. While creating a simple model consisting of an LSTM-layer and a linear activation layer. I wanted to overfit a small batch (n=2), to confirm that the loss dropped to zero. Overfitting a single sample (n=1) results in zero loss, as expected.
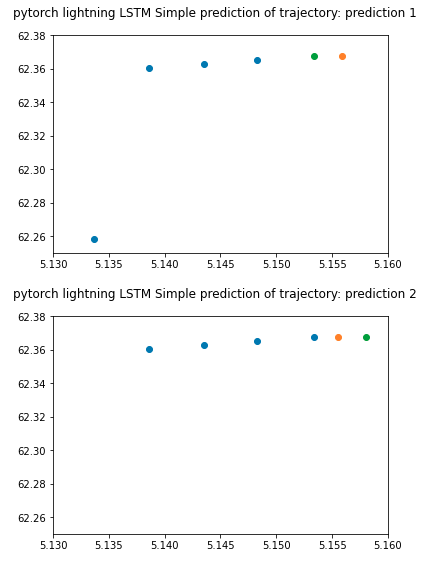
However, while trying to overfit the batch with n=2, it never drops to zero, both predictions converges to the average of the two correct positions in the batch. Something is clearly wrong with the model, but I am unsure of how to proceed. My best guess is that something is wrong with the input dimensions to the linear layer.
To illustrate the predictions, the sample plots are given, where the blue dots are input positions, the orange dot is the prediction, and the green dot is the “answer”. As we can see, the orange dot is in the same position for both trajectories.
I appreciate any and all feedback, and if this is the wrong place to ask for help, please tell me where to look!
Below I have provided a small reproducible example, which has pytorch_lightning, torch and matplotlib as dependencies.
import pytorch_lightning as pl
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
sequence_1 = [[5.13371, 62.25824], [5.13856, 62.36048], [5.143550, 62.362821], [5.14830, 62.36512]]
answer_1 = [5.153339, 62.36752]
sequence_2 = [[5.13856, 62.36048], [5.143550, 62.362821], [5.14830, 62.36512], [5.153339, 62.36752]]
answer_2 = [5.158045, 62.3675]
sequences = torch.Tensor([sequence_1, sequence_2]) # convert sequences to tensor
answers = torch.Tensor([answer_1, answer_2]) # convert answers to tensor
dataset = TensorDataset(sequences, answers) # create dataset from sequences and answers
dataset_loader = DataLoader(dataset, batch_size=2, num_workers=0) # create dataloader for use in pl.Trainer
class LightningLSTMRegressor(pl.LightningModule):
def __init__(self, output_size, input_size, hidden_size, num_layers, criterion, learning_rate):
super(LightningLSTMRegressor, self).__init__()
self.output_size = output_size
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.criterion = criterion
self.learning_rate = learning_rate
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, output_size)
self.linear.bias = torch.nn.Parameter(torch.tensor([6., 62.]))
def forward(self, x):
# hidden state and cell initialization
h0 = torch.zeros(
self.num_layers, x.size(0), self.hidden_size)
c0 = torch.zeros(
self.num_layers, x.size(0), self.hidden_size)
lstm_out, (ht, ct) = self.lstm(x, (h0, c0))
lstm_out = lstm_out[:, -1, :]
y_pred = self.linear(lstm_out)
return y_pred
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = self.criterion(y_hat, y)
self.log('train_loss', loss)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = self.criterion(y_hat, y)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
model_params={'learning_rate': 0.001,
'max_epochs': 5000,
'input_size': 2,
'output_size': 2,
'hidden_size': 5,
'num_layers': 1
}
criterion = torch.nn.MSELoss()
model = LightningLSTMRegressor(output_size=model_params['output_size'],
input_size=model_params['input_size'],
hidden_size=model_params['hidden_size'],
num_layers=model_params['num_layers'],
criterion=criterion,
learning_rate=model_params['learning_rate'])
pl.seed_everything(1000)
# set progress_bar_refresh_rate to 0, so that it doesnt crash colab
trainer = pl.Trainer(max_epochs=5000,
progress_bar_refresh_rate=1,
)
trainer.fit(model, dataset_loader)
def plot_prediction(input_sequence, prediction, answer, title):
plt.ylim(62.25, 62.38)
plt.xlim(5.13, 5.16)
input_sequence = list(zip(*input_sequence))
plt.scatter(input_sequence[0], input_sequence[1])
plt.scatter(prediction[0], prediction[1])
plt.scatter(answer[0], answer[1])
plt.suptitle('pytorch lightning LSTM Simple prediction of trajectory: ' + title)
plt.show()
predictions = model(sequences)
predictions_plot = predictions.data.numpy()
sequences_plot = sequences.data.numpy()
true_positions_plot = answers.data.numpy()
plot_prediction(sequences_plot[0], predictions_plot[0], true_positions_plot[0], "prediction 1")
plot_prediction(sequences_plot[1], predictions_plot[1], true_positions_plot[1], "prediction 2")
print(predictions)```