Hi,
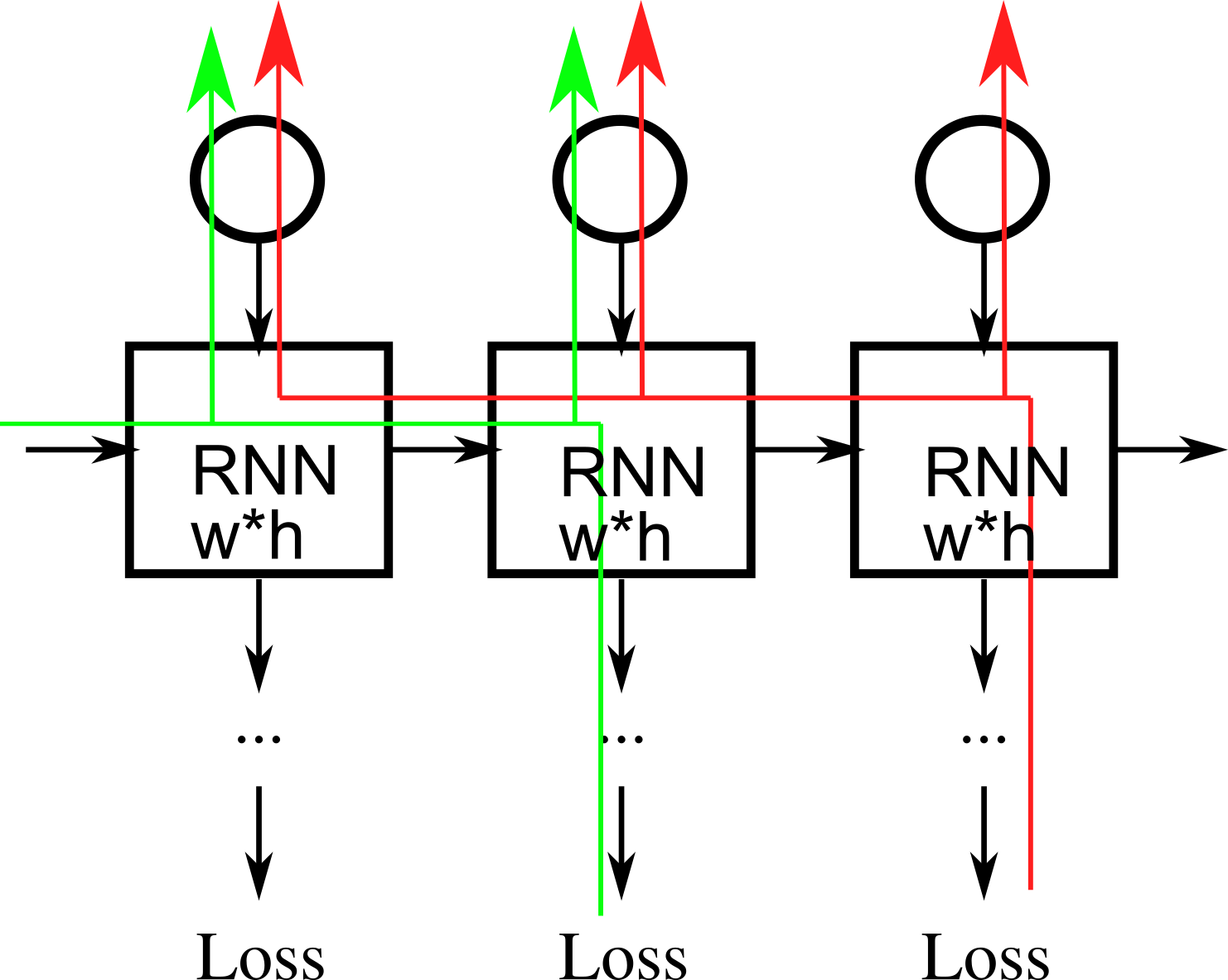
I am implementing an LSTMCell in order to predict a value (float) in a time series setting. In order to update the weights of the cell it makes sense to calculate the gradients of the weights over all previous states of the cell. However, as the time series are long this substantially reduces calculation speed. By running .detach() before every single input/output it is possible to update my weights in a timely fashion. However, a lot of information gets lost and training would work better if gradients on the weights from previous updates of the LSTM were taken into account as well. I am wondering whether it is possible to detach part of the history of calculations with respect to the weights, making it therefore faster to run .backward(). Specifically, is it possible to update the weights of the model taking only a window of the 10 previous time steps into account.
It seems this question has not been answered after an extensive amount of time. Can I have some feedback on whether the question is not clear (and I should rephrase) or whether what I’m asking for is simply not implemented.
Well, the usual thing to do is .detach() 10 steps before the end.
This won’t give you overlapping windows to backprop through, but it’s rather common (e.g. fast.ai’s language models do this and Jeremy explains it in the corresponding lecture).
I fear the .detach() functionality does not offer a clean solution in this case.
At this moment, if I want to backpropagate over a window of 3 timesteps, I need to perform the forward pass three times with different variables for which the histories have been deleted.
# written out without using loops and disregarding the input to keep it clean.
h3 = w*h0_det_2
h3_det = h3.detach()
h2_det_1 = w*h2_det
h1_det_2 = w*h1_det_1
h4 = w*h1_det_2
h4_det = h4.detach()
h3_det_1 = w*h3_det
h2_det_2 = w*h2_det_1
h5 = w*h2_det_2
h5_det = h5.detach()
h4_det_1 = w*h4_det
h3_det_2 = w*h3_det_1
h6 = w*h3_det_2
h6_det = h6.detach()
h5_det_1 = w*h5_det
h4_det_2 = w*h4_det_1
h7 = w*h4_det_2
h7_det = h7.detach()
h6_det_1 = w*h6_det
h5_det_2 = w*h5_det_1
...
# this possible (dirty) solution does not work
h7.grad_fn.next_functions[1][0].next_functions[1][0].next_functions = ()
h7.backward()
This solution is not very useful as it requires the forward pass of the RNN to be performed as many times as the amount of timesteps I want to backpropagate through.
It seems like there must be an easier solution to this.