Hello,
I am trying to deploy a pytorch model with dropout layers using torchscript into the c++ api. However, I run into an issue where the parameters which can be loaded using the regular python script and the torchscript model are different. When setting up the model by inheriting from torch.jit.ScriptModule (as is necessary to export the annotated model) I observe that for every dropout layer, a parameter named *.training which is empty is created and causes a problem when loading weights from a file stream, since the model weights exported from the model inherited from nn.Module don’t have a parameter associated with the dropout layers (see the example outputs below).
I realize that it is uncommon to preserve dropout layers outside of training, however in this case, the model is supposed to retain the dropout layers to exhibit stochastic behavior.
Below is 2 versions of the code i run for the model, one which uses pytorch and the other which i try to create a torchscript module, along with the code I have attached the output comparison between the state dictionary of the torchscript and the pytorch modules.
Below is the output from printing the first few parameters in the model state dictionary when the model is created using torch.jit.ScriptModule (notice the empty tensor parameter for layer 2, “fc.2.training”)
Model's state_dict: fc.0.bias torch.Size([1280])
fc.0.weight torch.Size([1280, 74])
fc.1.weight torch.Size([1])
fc.2.training torch.Size([])
fc.3.bias torch.Size([896])
fc.3.weight torch.Size([896, 1280])
Below is the output from printing the first few parameters in the model state dictionary when the model is created using nn.Module (here notice there is no parameter associated with layer 2)
Model's state_dict: fc.0.weight torch.Size([1280, 74])
fc.0.bias torch.Size([1280])
fc.1.weight torch.Size([1])
fc.3.weight torch.Size([896, 1280])
fc.3.bias torch.Size([896])
Below is a photo of the 2 python programs used to produce the results
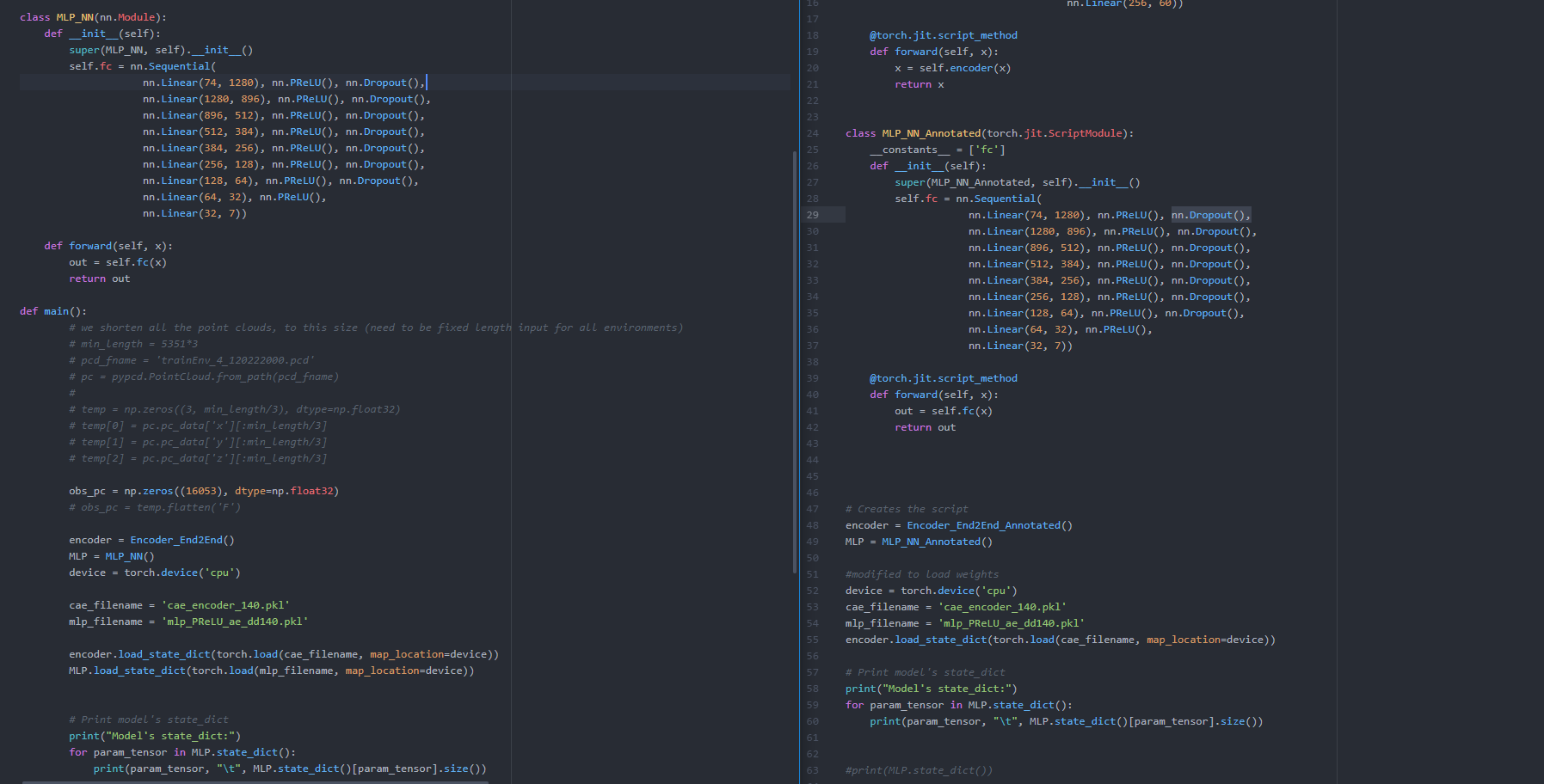
If anyone can help me figure out how to export my trained model so that I can load it into a C++ program with the dropout preserved, that would be much appreciated.