i tried training on qoura qeustion pair using MaLSTM


I use MSELoss has described in the paper, but it seems it is not learning anything
i tried training on qoura qeustion pair using MaLSTM
I use MSELoss has described in the paper, but it seems it is not learning anything
Could you post the code by wrapping it into three backticks ``` please? 
This would make debugging a lot easier and also would enable the forum search to index your code.
Thanks for your quick reply
class LSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, n_layers, drop_prob=0.5):
super(LSTM, self).__init__()
self.n_layers = n_layers
self.hidden_dim = hidden_dim
# embedding and LSTM layers
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, n_layers,
dropout=drop_prob, batch_first=True)
def forward(self,x,hidden):
embeds = self.embedding(x)
lstm_out, hidden = self.lstm(embeds,hidden)
return hidden[0]
def init_hidden(self, batch_size):
''' Initializes hidden state '''
# Create two new tensors with sizes n_layers x batch_size x hidden_dim,
# initialized to zero, for hidden state and cell state of LSTM
weight = next(self.parameters()).data
if (True):
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().cuda(),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().cuda())
else:
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_(),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_())
return hidden
and then create the MaLSTM here
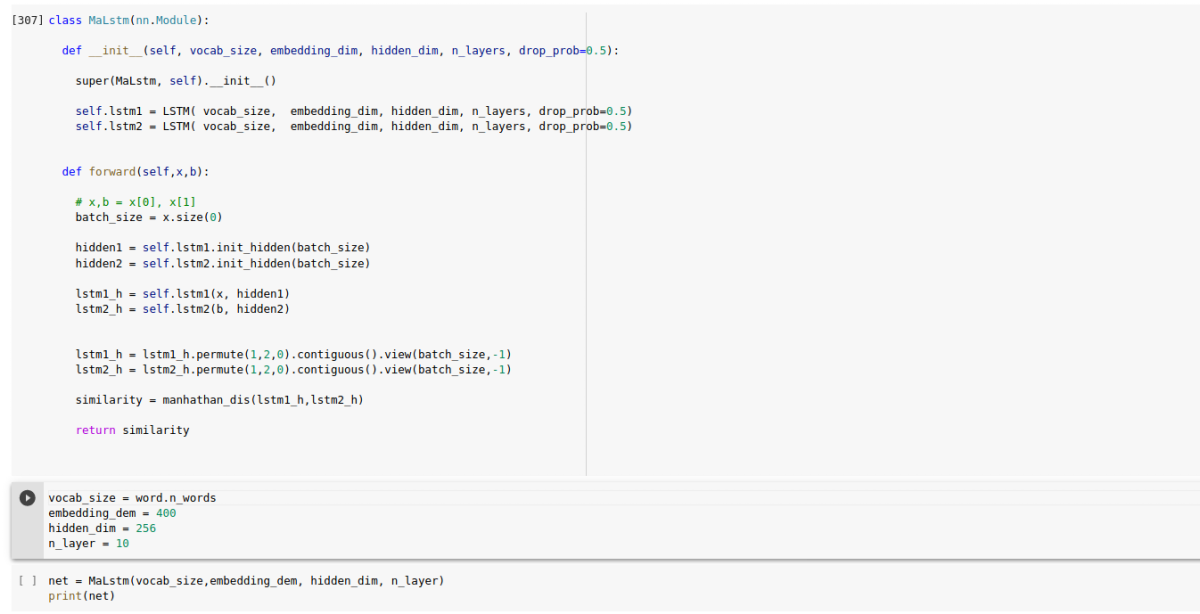
class MaLstm(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, n_layers, drop_prob=0.5):
super(MaLstm, self).__init__()
self.lstm1 = LSTM( vocab_size, embedding_dim, hidden_dim, n_layers, drop_prob=0.5)
self.lstm2 = LSTM( vocab_size, embedding_dim, hidden_dim, n_layers, drop_prob=0.5)
def forward(self,x,b):
# x,b = x[0], x[1]
batch_size = x.size(0)
hidden1 = self.lstm1.init_hidden(batch_size)
hidden2 = self.lstm2.init_hidden(batch_size)
lstm1_h = self.lstm1(x, hidden1)
lstm2_h = self.lstm2(b, hidden2)
lstm1_h = lstm1_h.permute(1,2,0).contiguous().view(batch_size,-1)
lstm2_h = lstm2_h.permute(1,2,0).contiguous().view(batch_size,-1)
similarity = manhathan_dis(lstm1_h,lstm2_h)
return similarity
vocab_size = word.n_words
embedding_dem = 400
hidden_dim = 256
n_layer = 10
net = MaLstm(vocab_size,embedding_dem, hidden_dim, n_layer)
lr = 0.001
criterion = nn.MSELoss()
optimizer = torch.optim.Adadelta(net.parameters(), lr=lr)
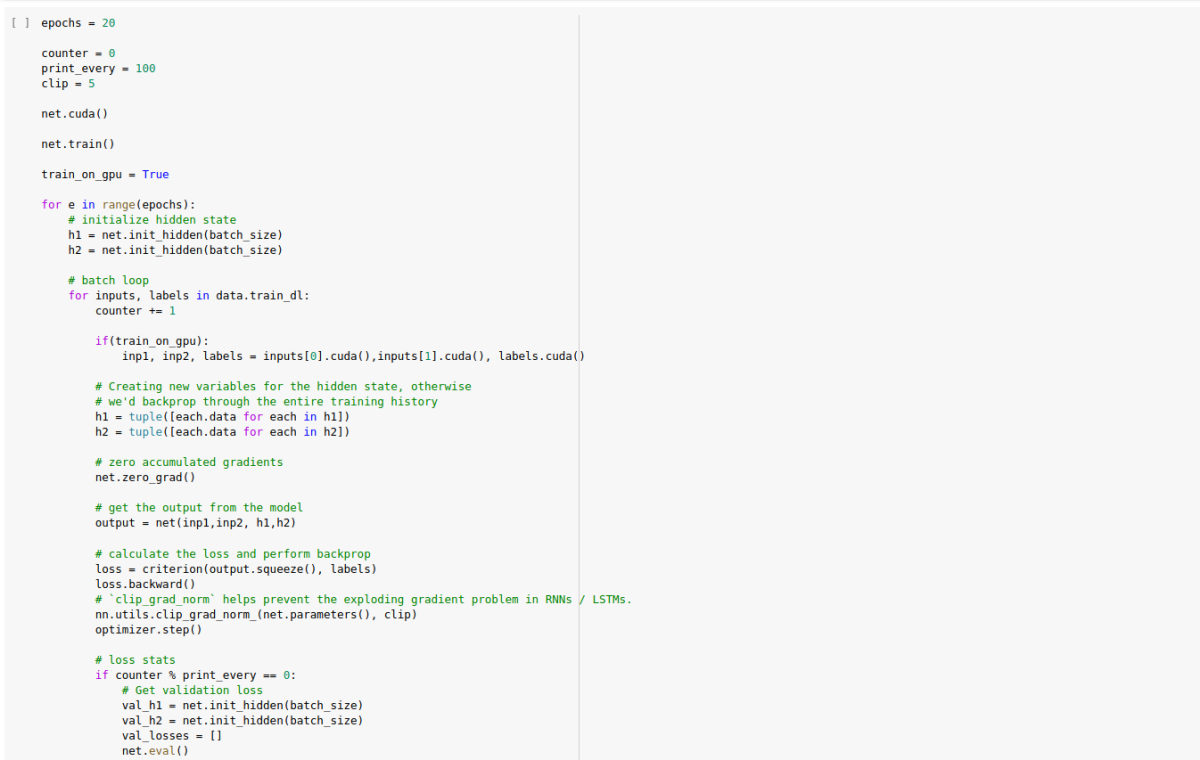
epochs = 20
counter = 0
print_every = 100
clip = 5
net.cuda()
net.train()
train_on_gpu = True
for e in range(epochs):
# initialize hidden state
# batch loop
for inputs, labels in data.train_dl:
counter += 1
if(train_on_gpu):
inp, labels = inputs.cuda(), labels.cuda()
# zero accumulated gradients
net.zero_grad()
# get the output from the model
output = net(inp1)
# calculate the loss and perform backprop
loss = criterion(output, labels)
loss.backward()
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
nn.utils.clip_grad_norm_(net.parameters(), clip)
optimizer.step()
# loss stats
if counter % print_every == 0:
# Get validation loss
val_losses = []
net.eval()
for inputs, labels in data.valid_dl:
if(train_on_gpu):
inp, labels = inputs.cuda(),labels.cuda()
output, val_h = net(inp)
val_loss = criterion(output, labels)
val_losses.append(val_loss.item())
net.train()
print("Epoch: {}/{}...".format(e+1, epochs),
"Step: {}...".format(counter),
"Loss: {:.6f}...".format(loss.item()),
"Val Loss: {:.6f}".format(np.mean(val_losses)))
output
Epoch: 2/20... Step: 100... Loss: 0.450000... Val Loss: 0.380000
Epoch: 3/20... Step: 200... Loss: 0.150000... Val Loss: 0.380000
Epoch: 4/20... Step: 300... Loss: 0.400000... Val Loss: 0.380000
Epoch: 5/20... Step: 400... Loss: 0.350000... Val Loss: 0.380000
Epoch: 6/20... Step: 500... Loss: 0.550000... Val Loss: 0.380000
Epoch: 7/20... Step: 600... Loss: 0.450000... Val Loss: 0.380000
Epoch: 8/20... Step: 700... Loss: 0.350000... Val Loss: 0.380000
Epoch: 9/20... Step: 800... Loss: 0.400000... Val Loss: 0.380000
Epoch: 10/20... Step: 900... Loss: 0.400000... Val Loss: 0.380000
Epoch: 12/20... Step: 1000... Loss: 0.450000... Val Loss: 0.380000
Epoch: 13/20... Step: 1100... Loss: 0.400000... Val Loss: 0.380000
Epoch: 14/20... Step: 1200... Loss: 0.400000... Val Loss: 0.380000
Epoch: 15/20... Step: 1300... Loss: 0.350000... Val Loss: 0.380000
Epoch: 16/20... Step: 1400... Loss: 0.450000... Val Loss: 0.380000
Epoch: 17/20... Step: 1500... Loss: 0.400000... Val Loss: 0.380000
Epoch: 18/20... Step: 1600... Loss: 0.300000... Val Loss: 0.380000
Epoch: 19/20... Step: 1700... Loss: 0.450000... Val Loss: 0.380000
Epoch: 20/20... Step: 1800... Loss: 0.200000... Val Loss: 0.380000
thanks a lot
i forgot to add the manhathan distance
def manhathan_dis(f,s):
return torch.exp(-torch.sum(torch.abs(f-s), dim=1))
The training loss seems to go down, while the validation loss is constant.
Could you check the model output during training and validation and compare the training and validation data distribution?
ok i will do that now.
But did i get the implementation right?
and when u say distribution; You mean i should check the mean and the std if they are (near 0 and 1)?
I’ve checked the output they are all zero
train output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
train output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
train output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
train output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
train output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
train output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
validation output tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', grad_fn=<ExpBackward>)
is it because for every model.forward(x) i’m always doing init_hidden(batch_size)
def forward(self,x,b):
# x,b = x[0], x[1]
batch_size = x.size(0)
hidden1 = self.lstm1.init_hidden(batch_size)
hidden2 = self.lstm2.init_hidden(batch_size)
lstm1_h = self.lstm1(x, hidden1)
lstm2_h = self.lstm2(b, hidden2)
If you are using the same workflow during training, I would assume it should be fine to use it during validation.