Hi,
I have a question when using Pytorch for my experiments. I am not sure if I used a very appropriate title to address this, but I’ll describe it in details below.
I am working on building text models using LSTM. Below is the snapshot of my original code:
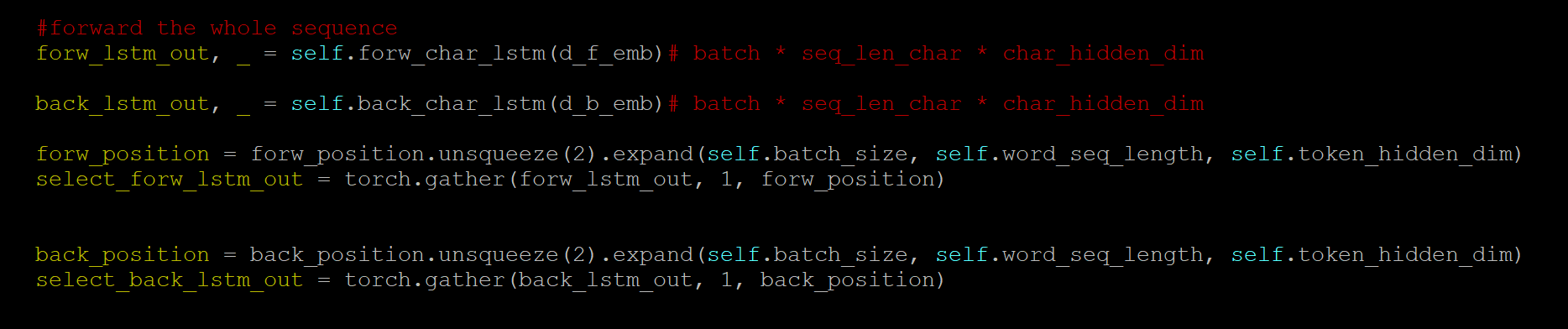
Basically what I am doing is to feed the character level embedding of each word inside a sentence into a LSTM and gather the output of the LSTM of the last character of each word.
So the output of the LSTM(which is the forw_lstm_out and back_lstm_out in the code) have a shape of:
batch_size * seq_len_char * char_hidden_dim, where seq_len_char is the padded length of all the characters in a sentence(number of all the characters in a sentence) and char_hidden_dim is the hidden dimension of the LSTM cell. In forw_position, it stores the positions of the last character of each word. So for example, if the sentence is “I almost returned it”, then the forw_position will store something like [0, 7, 16, 18] which correspond to [‘I’, ‘t’, ‘d’, ‘t’]. And forw_position are padded as well in order to be processed in batch. So the shape of forw_position will be batch_size * word_len * char_hidden_dim, where word_len is the padded word length(number of words in a sentence).
So the gathering operation will gather the output of the LSTM of the last character of each word in the sentence to represent the embedding of each word.
What I want to do now is to instead of using the output of the last character, I want to use the average output of all the characters in a word. For example, for word “almost”, instead of using the output for just ‘t’ which is the last character, I want to use the average of the output of all the characters (‘a’, ‘l’, ‘m’, ‘o’, ‘s’, ‘t’) to represent the embedding for word “almost”.
I thought about using masks like this:
Given LSTM out which has shape of [batch_size * seq_len_char * char_hidden_dim], I will create a mask which has a shape of [batch_size * word_len * seq_len_char * char_hidden_dim]. And in this mask, on the third dimension which is the seq_len_char dimension, I will use 0/1 to indicate the characters of a word. But I am not sure how to exactly perform matrix multiplication for these two matrices. Or is there better way to do this? Could someone help me on this? Thank you so much!