Are you seeing this behavior using a specific model or always?
In any case, could you post a minimal code snippet to reproduce this behavior as well as your current setup (PyTorch, CUDA, cudnn versions, which GPU you are using etc.)?
thank you for reply!
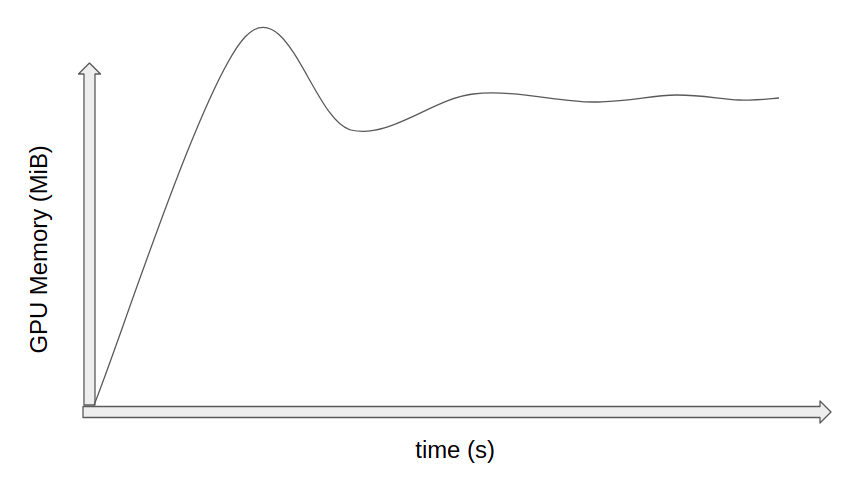
I thought this is generally happens
this is code I use for train
disp_L = model(imgL, imgR)
loss = F.smooth_l1_loss(dispL, dispL_GT, size_average=True)
optimizer.zero_grad()
loss.backward() # here is peak of overshoot in iteration 1
optimizer.step()
current environment
model : any model(ex. PSMNet, Segment, yoloV4, …)
GPU : RTX 2070
CUDA : CUDA 11
pytorch : 1.7
Could you post an executable code snippet, which raises the OOM issue on this device, please?
The memory peak might increase e.g. if cudnn uses its benchmarking to profile different kernels.
However, this should not raise an OOM error, but skip the algorithm and clear the cache afterwards.