Hey guys, I want to implement this cyclic function:
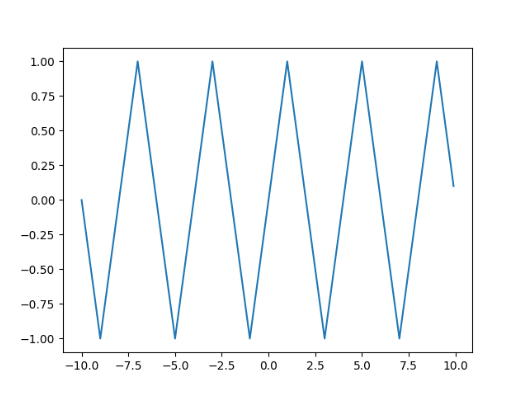
Specifically, I first implement it by the combination of five Pytorch ops.
def origin_op(x):
x = torch.add(x, -1)
x = torch.remainder(x, 4)
x = torch.add(x, -2)
x = torch.abs(x)
x = torch.add(x, -1)
return x
However, it is rather slow so I re-implement it in CUDA.
template <typename scalar_t>
__device__ __forceinline__ scalar_t forward1(scalar_t z) {
auto res = fmod(z-1,(scalar_t)4);
res += res<0?(scalar_t)2:-2;
return res; // will be cached for backward
}
template <typename scalar_t>
__device__ __forceinline__ scalar_t forward2(scalar_t z) {
const auto res = fabs(z) - 1;
return res;
}
template <typename scalar_t>
__device__ __forceinline__ scalar_t backward(scalar_t tmp, scalar_t d_output) {
const auto res = tmp>0? d_output:-d_output;
return res;
}
Then I test the speed of each op and get
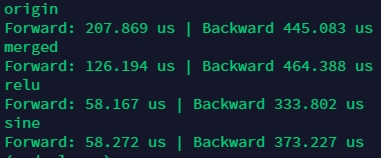
I am confused:
- Why the speed of backward is even SLOWER than the original implementation?
- Why torch.sin is as fast as relu?
Looking forward to somebody’s help~