Hi,
I have a very deep model and I am trying to implement model sharding as its not working on a single GPU. Code is below:
class ConvolutionalAutoEncoder(nn.Module):
def __init__(self):
super(ConvolutionalAutoEncoder, self).__init__()
self.encoder_block1 = nn.Sequential(
nn.Conv2d(1, 64, 3, stride=1, padding=1),
nn.Tanh(),
nn.Conv2d(64, 64, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(64)
)
self.encoder_block2 = nn.Sequential(
nn.Conv2d(64, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(128)
)
self.encoder_block3 = nn.Sequential(
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(128)
)
self.encoder_block4 = nn.Sequential(
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(128)
)
self.decoder_block4 = nn.Sequential(
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(128)
)
self.decoder_block3 = nn.Sequential(
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(128)
)
self.decoder_block2 = nn.Sequential(
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(128)
)
self.decoder_block1 = nn.Sequential(
nn.ConvTranspose2d(128, 64, 3, stride=1, padding=1),
nn.Tanh(),
nn.ConvTranspose2d(64, 64, 3, stride=1, padding=1),
nn.Tanh(),
nn.BatchNorm2d(64)
)
self.decoder_block0 = nn.Sequential(
nn.ConvTranspose2d(64, 1, 3, stride=1, padding=1),
)
self.encoder_block1 = self.encoder_block1.to('cuda:0')
self.encoder_block2 = self.encoder_block2.to('cuda:0')
self.encoder_block3 = self.encoder_block3.to('cuda:1')
self.encoder_block4 = self.encoder_block4.to('cuda:1')
self.decoder_block4 = self.decoder_block4.to('cuda:2')
self.decoder_block3 = self.decoder_block3.to('cuda:2')
self.decoder_block2 = self.decoder_block2.to('cuda:3')
self.decoder_block1 = self.decoder_block1.to('cuda:3')
self.decoder_block0 = self.decoder_block0.to('cuda:3')
def forward(self, x):
x1 = self.encoder_block1(x)
x2 = self.encoder_block2(x1)
x2 = x2.to('cuda:1')
x3 = self.encoder_block3(x2)
x4 = self.encoder_block4(x3)
x4 = x4.to('cuda:2')
x3 = x3.to('cuda:2')
y4 = self.decoder_block4(x4)
y3 = self.decoder_block3(y4+x3)
y3 = y3.to('cuda:3')
x2 = x2.to('cuda:3')
y2 = self.decoder_block2(y3+x2)
y1 = self.decoder_block1(y2)
y0 = self.decoder_block0(y1)
return y0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
model = ConvolutionalAutoEncoder()
learning_rate = 0.001
weight_decay = 0.1
momentum = 0.9
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
params = list(model.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
num_epochs = 30
for epoch in range(num_epochs):
for i, data in enumerate(train_loader):
inp, targ = data
inp = inp.to(device)
targ = targ.to(device)
output = model(inp)
output = output.to(device)
optimizer.zero_grad()
loss = F.binary_cross_entropy_with_logits(output, targ)
loss.backward()
optimizer.step()
if i % 10 == 0:
for param_group in optimizer.param_groups:
print("Current learning rate is: {}".format(param_group['lr']))
print("Epoch[{}/{}]({}/{}): Loss: {:.4f}".format(epoch+1,num_epochs, i, len(train_loader), loss.item()))
The code runs and I think the forward pass works well. I can see the load being passed to the different GPU’s but after one pass it stops working and the code just hangs. I cant even kill it and the only way to get out is to force reboot.
Screenshot of nvidia-smi also attached:
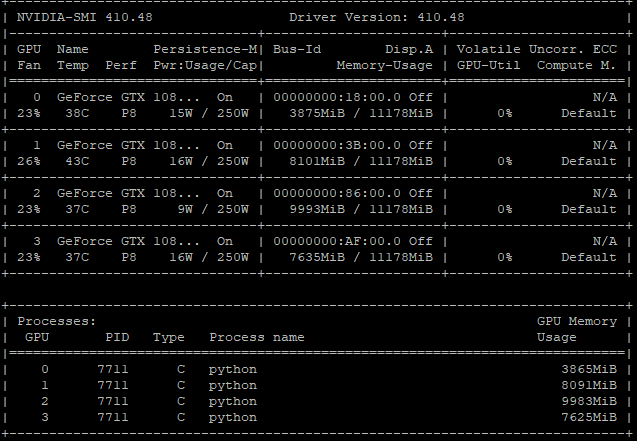
No matter how much I try to kill the process (7711), it does not stop.
Is there something wrong with my code?
Please help.
EDIT:
Ok. So I think I solved the problem. I was computing the loss function in cuda 0 but the last layer was in cuda 3, hence I think it was causing problem while backward propagating (not sure why it didnt throw an error but just froze completely).
So I moved the loss function also to cuda 3 and it worked!!! ![]()
But I dont know why but I am not able to print the loss value i.e.
if i % 10 == 0:
print("Epoch[{}/{}]({}/{}): Loss: {:.4f}".format(epoch+1,num_epochs, i, len(train_loader), loss.item()))
The code’s freezing up in this part. Why is just printing the loss causing a problem?