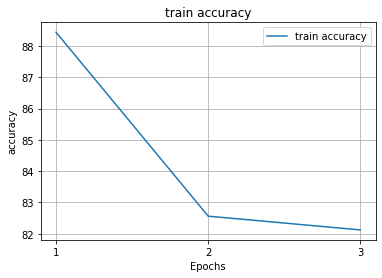
I had really good results(at least in test and accuracy), as I’ve trained model for 3 epochs on the thermal images dataset to output coordinates of moving object. For that purpose I used cnn, maxpool, lstm and linear layers.
As deviation with the target coordinates was in 1e-2 field, I decided to try out printing coordinates on the video itself, so i changed model from train() to eval() modes and gave the model the before used training video frames, with torch.zero_grad() decorator above.
Results were way far away from those I had previously. My accuracy(sum of the absoluted difference of predict and target x,y coordinates) in the training case was in 80% of all frames not greater than one pixel. Now im having worst ever results. Can somebody say how it can be possible that evaluation on the same samples, which were used for training can be soo bad??
Here Im gonna also post the general network performance and its structre.
Model:
(conv1): Conv2d(1, 40, kernel_size=(6, 6), stride=(5, 5))
(conv2): Conv2d(40, 40, kernel_size=(5, 5), stride=(2, 2), padding=(1, 1))
(conv3): Conv2d(40, 120, kernel_size=(3, 4), stride=(3, 3))
(relu0): ReLU()
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten1): Flatten(start_dim=1, end_dim=-1)
(lstm): LSTM(20, 175, num_layers=2)
(flatten2): Flatten(start_dim=0, end_dim=-1)
(linear3): Linear(in_features=21000, out_features=2, bias=True)
)
Optimizer:
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
capturable: False
differentiable: False
eps: 1e-08
foreach: None
fused: False
lr: 0.0005
maximize: False
weight_decay: 0
)