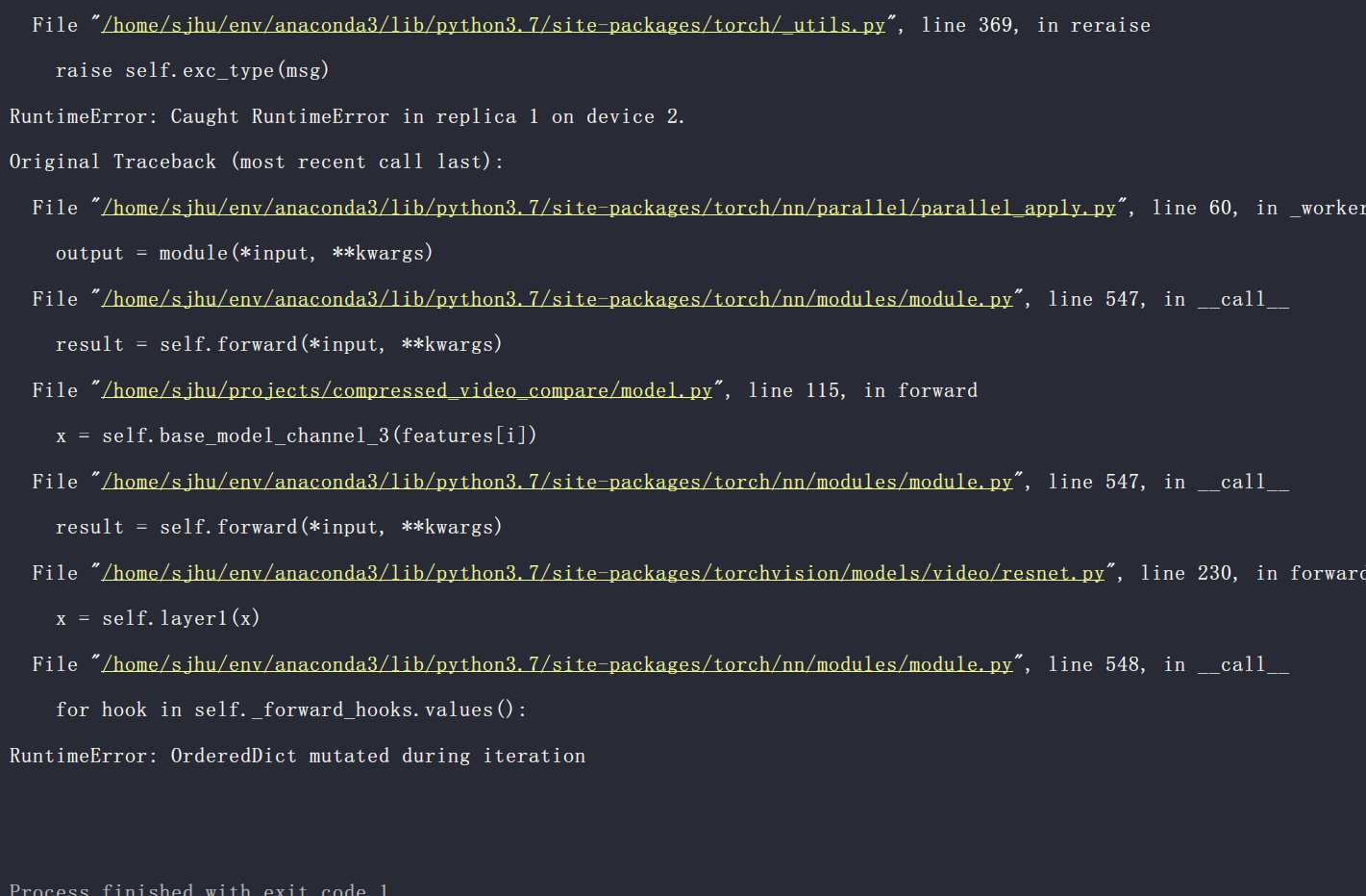
my code looks like this, i write a forward hook,and try to move ‘QPs’ to the ‘output’ tensor device then do some operations, but my ‘assert’ code failed , because two tensor are not on the same device, i am confused…BTY,i use dataparallel but i think it doesn’t matter… so what happens?
You need to do QPs = QPs.to(output.device) for it to work as to does not change the Tensor inplace.
Also you can try QPs = output.new(QPs, device=output.device).
ok, i think ,there exists a little bug in nn/module/module.py, in ‘call’ function, i change the line
for hook in self._forward_hooks.values():
to
for hook in list(self._forward_hooks.values()):
and the code will be fine.
The following code is the changed module.py -‘call()’ func:
def __call__(self, *input, **kwargs):
for hook in list(self._forward_pre_hooks.values()):
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
for hook in list(self._forward_hooks.values()):
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in list(self._backward_hooks.values()):
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
I guess this works because creating the list makes a copy of the hooks data stucture and hides the error.
But the error is still there that you change the hooks during while you run them. Is that what you’re doing?
right…i have a dynamic weight matrix, and in every time forward process i register the forward hook,change the hook output, then remove it, in model ‘forward’ func. i wonder if i register the hook in model ‘init’ func, the variable QP doesn’t get right value, because the QP is changed by specific input,the forward hook will change the output correctly? if that case, where should i register the forward hook and where should i remove it? i am little confused by the hook mechanic, thanks !
def layer1_hook_fn_forward(module, input, output):
# output shape 2, 64, 10, 56, 56
global QPs #it's a variable
a = QPs.to(output.device)
assert a.device == output.device, "tensor device not match"
return output.mul(a)
def forward(self, inputs):
# ( (img1,mv1,qp1), (img2,mv2,qp2))
outputs = []
for features in inputs:
mix_features = []
global QPs
QPs = self.deal_qp_data(features[2]) #change by input
# print(next(self.qp_model.parameters()).is_cuda)
for i in range(len(features)):
if i == 0:
# for rgb
features[i] = self.data_bn_channel_3(features[i])
handle1 = self.base_model_channel_3.layer1.register_forward_hook(layer1_hook_fn_forward)
x = self.base_model_channel_3(features[i])
handle1.remove()
if i == 1:
# for mv and residual need batch_normalization
features[i] = self.data_bn_channel_2(features[i])
handle2 = self.base_model_channel_2.layer1.register_forward_hook(layer1_hook_fn_forward)
x = self.base_model_channel_2(features[i])
handle2.remove()
if i == 2:
continue
x = self.dropout(x)
x = self.key_feature_layer(x)
# x = (batch, features)
mix_features.append(x)
mix_features = torch.cat([mix_features[0], mix_features[1]], dim=1)
# print(mix_features.shape)
outputs.append(mix_features)
x = self.fc_layer_1(torch.abs(outputs[0] - outputs[1]))
x = F.relu(x)
x = self.fc_layer_2(x)
x = torch.sigmoid(x)
x = self.clf_layer(x)
return outputs, x
i write the following code to test ,it’ right, but the last code segment is still wrong, so the error means i change the hook during running? besides my model is a DataParallel model… so where is the problem…i am thinking.
import torch
from torch import nn
import numpy as np
QP = []
class SimpleConv(nn.Module):
def __init__(self):
super(SimpleConv, self).__init__()
self.layer1 = nn.Linear(1,32)
self.layer2 = nn.Linear(32,64)
def forward(self, x):
global QP
QP = np.repeat(x,32)
handle = self.layer1.register_forward_hook(layer1_hook_fn_forward)
x = self.layer1(x)
handle.remove()
x = self.layer2(x)
return x
def layer1_hook_fn_forward(module, input, output):
# this hook will change the output
global QPs
a = QP.to(output.device)
assert a.device == output.device, "tensor device not match"
return output.mul(a)
for i in range(50):
model = SimpleConv()
a= torch.tensor([1.0])
model(a)
yeah,i can run this sample without errors too, but my real project code is still wrong…if i change the source code like pre post and make the project can run, from the view of hook function that change the layer output, can i do that?
I mean, now my example can run through, but my project will still report an error. In my previous post, I can modify the code in the ‘module.py’ so that the project does not report an error, but you said that the error still exists, but I want to know if this still existing error will affect my purpose of using hooks, that is, modifying the layer output results.
I am not sure exactly what will happen here.
Most likely, since the hook list was copied before, all the original hooks will run irrelevant of how you modify them during the for loop.
The bigger problem is that it is going to be complex for you to keep changing the module.py file to hack around the problem in your code. In the mid/long term, it will be more time efficient I think to fix your code.