Hi,
When allocating a tensor on cuda:1 device and using str() on this tensor, memory is allocated on cuda:0.
Why is this ? Is my tensor copied to cuda:0 ?
I am using version 0.4.1 on linux with python 3.6
The following code reproduces the problem:
import torch
t = torch.zeros((4,3), device='cuda:1') # allocation in done on cuda:1, as expected
s = str(t) # allocates on cuda:0
Screen capture from nvidia-smi after the call to str(t)
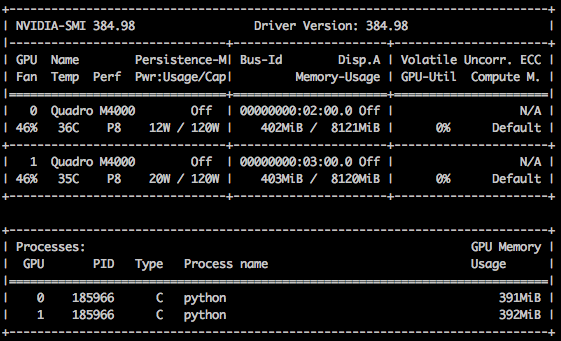
thanks !