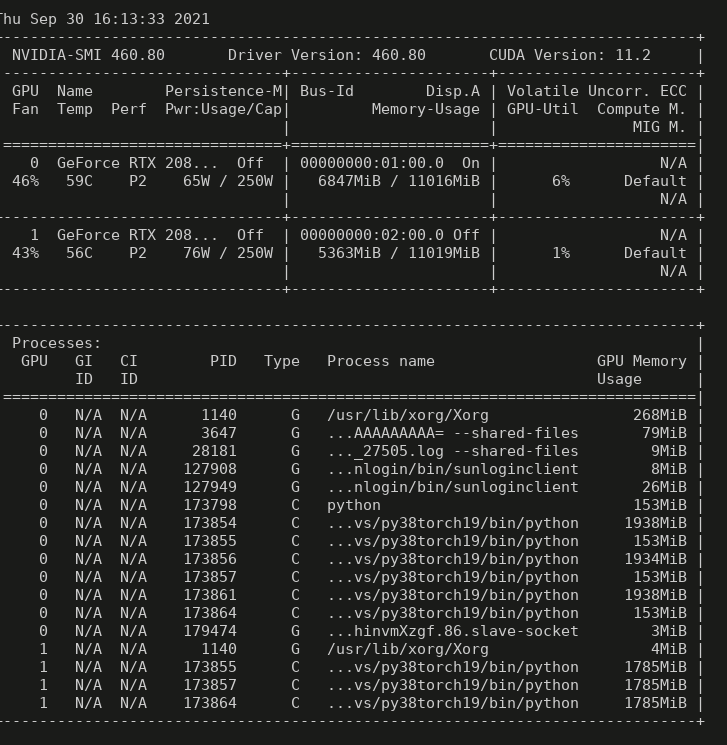
I use 2 GPUs for multi-process inference. I load models in the main process and put them to different GPUs in the sub-processes. However, I find that the processes of gpu1 always occupy 153M memory of gpu0.
import torch.multiprocessing as multiprocessing
multiprocessing.set_sharing_strategy('file_system')
...
def main(self):
...
self.create_model()
multiprocessing.set_start_method('spawn', force=True)
print('>>> multi-processes running <<<')
param_list = [([video_idx, video_name, im_list, gt_list, lang, len(seqs)],
self.tester_cfg.num_gpu)
for video_idx, (video_name, im_list, gt_list, lang) in enumerate(seqs)]
with multiprocessing.Pool(processes=self.tester_cfg.num_process) as pool:
pool.starmap(self.sub, param_list)
def sub(self, seq_info, num_gpu):
video_idx, video_name, im_list, gt_list, lang, seq_num = seq_info
worker_name = multiprocessing.current_process().name
worker_id = int(worker_name.split('-')[1]) - 1
gpu_id = worker_id % num_gpu
torch.cuda.set_device(gpu_id)
rank = worker_id
print('start rank {} on gpu {}'.format(rank, gpu_id))
self.model_to_device()
...