Hello all,
I am trying to make a CNN model for Encoder Parameter Suggestion for Audio data
Input: Audio File(Length : 480000 samples)
Output: Parameter(Length : 469, eg :[0001111222001233312000] )
I am getting very low Validation and Test Accuracy
for epoch in range(E):
for batch in range(B)
pred_1= model(training_data)
loss = loss_fn(pred_1, Target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Can Anybody suggest any other approach to rectify it.
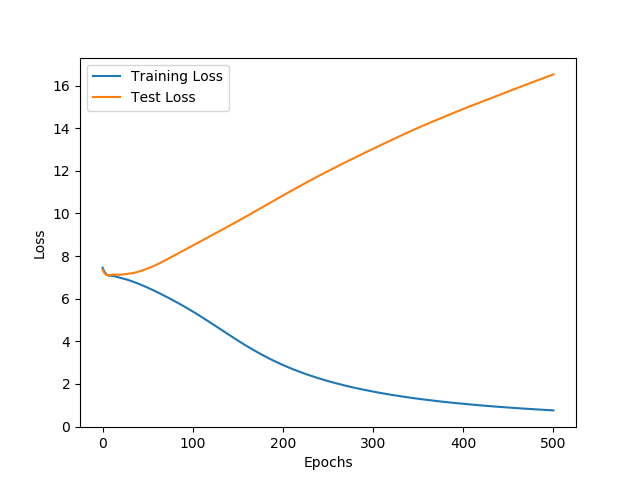
What about you training loss and training accuracy? If it is good, then your model is overfitting (which would be surprising given that it is quite simple), if not, then your model is probably too simple for the task
Are the classes balanced? If you have 1000 classes but 92% of your examples are of one class, then you can get an accuracy of 92% just by always predicting the same class. What kind of error does your model makes? Have a look at the predictions (training and validation) to check that they make sense
If class imbalance is not an issue, then you might try different techniques against overfitting incl. (but not limited to): adding dropout, adding a regularisation term, decreasing the capacity of your network, etc.
Hard to say without seeing the data. How did you build your test set? Is it a sample from your original dataset or does it come from another source? What about the training set distribution (see my previous question)? How much example in each subset? With no information, it’s hard to make recommendations…