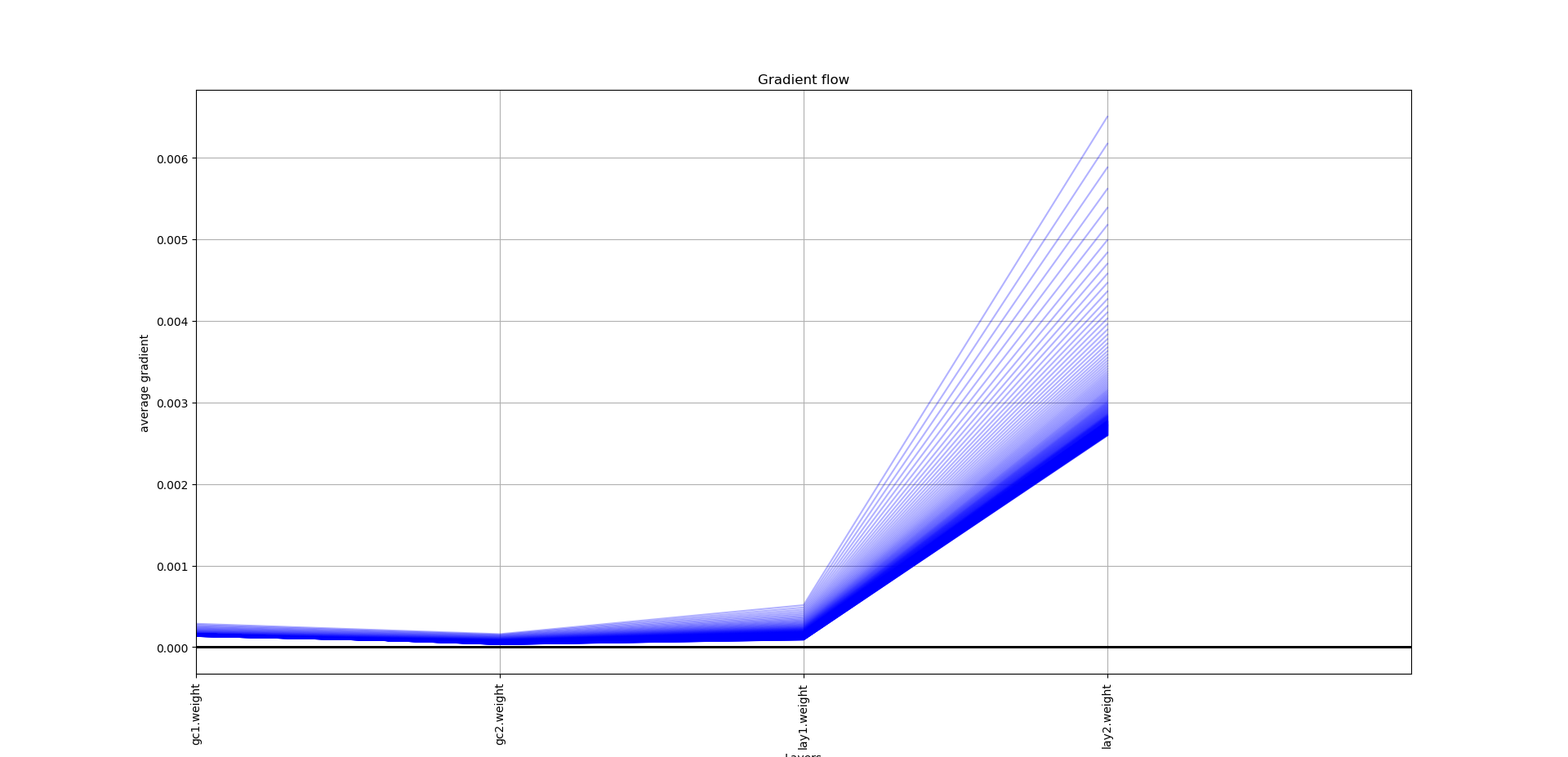
I’m having a similar problem, and I’ve discovered where in the process the NaN is being produced, but I’m not sure why or how I can go about fixing it. I’m currently just trying to overfit to a single training example as a sanity check for model selection.
I’m using the mean distance between spherical coordinates as loss function (I’ve also experimented using MSE and RMSE but it doesn’t make a different to the loss becoming NaN) the code for this is below.
def distance_between_spherical_coordinates_rad(az1, ele1, az2, ele2, deg=True):
"""
Angular distance between two spherical coordinates
MORE: https://en.wikipedia.org/wiki/Great-circle_distance
:return: angular distance in degrees or radians
"""
dist = torch.sin(ele1) * torch.sin(ele2) + torch.cos(ele1) * torch.cos(ele2) * torch.cos(torch.abs(az1 - az2))
# Making sure the dist values are in -1 to 1 range, else np.arccos kills the job
dist = torch.clip(dist, -1, 1)
if deg == True:
dist = torch.arccos(dist) * 180 / torch.pi
else:
dist = torch.arccos(dist)
return torch.sqrt(torch.mean(dist ** 2))
There appears to be no NaN values in the input or target and I’ve checked this with the below code.
with torch.autograd.detect_anomaly():
for i in range(runs):
optimizer.zero_grad()
preds = model(batch_input)
preds = utils.cart2sph(preds, deg=False)
batch_target_sph = utils.cart2sph(batch_target,deg=False)
if torch.isnan(preds[0]).any():
pass # breakpoint is here
if torch.isnan(preds[1]).any():
pass # breakpoint is here
if torch.isnan(batch_target_sph[0]).any():
pass # breakpoint is here
if torch.isnan(batch_target_sph[1]).any():
pass # breakpoint is here
loss = utils.distance_between_spherical_coordinates_rad(preds[0],preds[1], batch_target_sph[0], batch_target_sph[1])
# loss = loss_fn(preds,batch_target)
loss.backward()
optimizer.step()
When running the training loop I get the below error message generated by the anomaly detector
[W ..\torch\csrc\autograd\python_anomaly_mode.cpp:104] Warning: Error detected in AcosBackward0. Traceback of forward call that caused the error:
File "D:/Dan_PC_Stuff/Pycharm_projects/sceneGeneration/train.py", line 57, in <module>
loss = utils.distance_between_spherical_coordinates_rad(preds[0],preds[1], batch_target_sph[0], batch_target_sph[1])
File "D:\Dan_PC_Stuff\Pycharm_projects\sceneGeneration\utils.py", line 261, in distance_between_spherical_coordinates_rad
dist = torch.arccos(dist) * 180 / torch.pi
(function _print_stack)
Traceback (most recent call last):
File "D:/Dan_PC_Stuff/Pycharm_projects/sceneGeneration/train.py", line 60, in <module>
loss.backward()
File "C:\Users\Audio\anaconda3\lib\site-packages\torch\_tensor.py", line 307, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "C:\Users\Audio\anaconda3\lib\site-packages\torch\autograd\__init__.py", line 154, in backward
Variable._execution_engine.run_backward(
RuntimeError: Function 'AcosBackward0' returned nan values in its 0th output.
It seems to be happening within the backwards pass of the loss function, specifically the pass through dist = torch.arccos(dist) * 180 / torch.pi which is odd as that line of code shouldn’t triggered as I’ve got deg=False within the training loop.