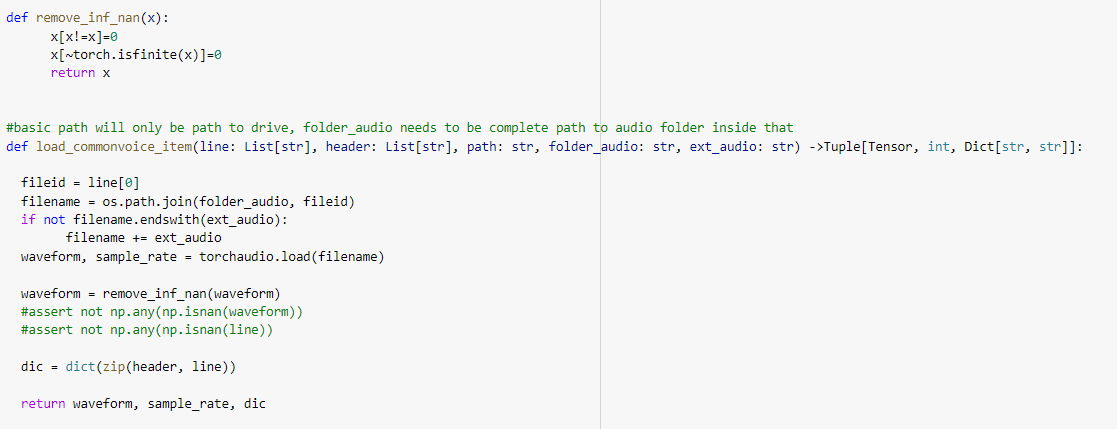
I’m training an urdu speech recognition model on the mozilla commonvoice dataset. It starts training fine initially, but after a certain while it starts giving nan as the loss. I’m not sure why it’s doing that or how to fix it. Saw people recommend reducing the learning rate or normalizing the data, but I don’t think any of those things will solve the problem here - already have normalization layers in my model, and the loss seems to be converging before it randomly starts giving nan, so I don’t think the learning rate is the issue. Any idea how to fix this?
The model:
class CNNLayerNorm(nn.Module):
“”“Layer normalization built for cnns input”“”
def init(self, n_feats):
super(CNNLayerNorm, self).init()
self.layer_norm = nn.LayerNorm(n_feats)
def forward(self, x):
# x (batch, channel, feature, time)
x = x.transpose(2, 3).contiguous() # (batch, channel, time, feature)
x = self.layer_norm(x)
return x.transpose(2, 3).contiguous() # (batch, channel, feature, time)
class ResidualCNN(nn.Module):
“”“Residual CNN inspired by https://arxiv.org/pdf/1603.05027.pdf
except with layer norm instead of batch norm
“””
def init(self, in_channels, out_channels, kernel, stride, dropout, n_feats):
super(ResidualCNN, self).init()
self.cnn1 = nn.Conv2d(in_channels, out_channels, kernel, stride, padding=kernel//2)
self.cnn2 = nn.Conv2d(out_channels, out_channels, kernel, stride, padding=kernel//2)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.layer_norm1 = CNNLayerNorm(n_feats)
self.layer_norm2 = CNNLayerNorm(n_feats)
def forward(self, x):
residual = x # (batch, channel, feature, time)
x = self.layer_norm1(x)
x = F.gelu(x)
x = self.dropout1(x)
x = self.cnn1(x)
x = self.layer_norm2(x)
x = F.gelu(x)
x = self.dropout2(x)
x = self.cnn2(x)
x += residual
return x # (batch, channel, feature, time)
class BidirectionalGRU(nn.Module):
def __init__(self, rnn_dim, hidden_size, dropout, batch_first):
super(BidirectionalGRU, self).__init__()
self.BiGRU = nn.GRU(
input_size=rnn_dim, hidden_size=hidden_size,
num_layers=1, batch_first=batch_first, bidirectional=True)
self.layer_norm = nn.LayerNorm(rnn_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.layer_norm(x)
x = F.gelu(x)
x, _ = self.BiGRU(x)
x = self.dropout(x)
return x
class SpeechRecognitionModel(nn.Module):
def __init__(self, n_cnn_layers, n_rnn_layers, rnn_dim, n_class, n_feats, stride=2, dropout=0.1):
super(SpeechRecognitionModel, self).__init__()
n_feats = n_feats//2
self.cnn = nn.Conv2d(1, 32, 3, stride=stride, padding=3//2) # cnn for extracting heirachal features
# n residual cnn layers with filter size of 32
self.rescnn_layers = nn.Sequential(*[
ResidualCNN(32, 32, kernel=3, stride=1, dropout=dropout, n_feats=n_feats)
for _ in range(n_cnn_layers)
])
self.fully_connected = nn.Linear(n_feats*32, rnn_dim)
self.birnn_layers = nn.Sequential(*[
BidirectionalGRU(rnn_dim=rnn_dim if i==0 else rnn_dim*2,
hidden_size=rnn_dim, dropout=dropout, batch_first=i==0)
for i in range(n_rnn_layers)
])
self.classifier = nn.Sequential(
nn.Linear(rnn_dim*2, rnn_dim), # birnn returns rnn_dim*2
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(rnn_dim, n_class)
)
def forward(self, x):
x = self.cnn(x)
x = self.rescnn_layers(x)
sizes = x.size()
x = x.view(sizes[0], sizes[1] * sizes[2], sizes[3]) # (batch, feature, time)
x = x.transpose(1, 2) # (batch, time, feature)
x = self.fully_connected(x)
x = self.birnn_layers(x)
x = self.classifier(x)
return x
The training: