I’m using a CNN+LSTM model with CTC loss for an OCR task. I use the null character as the target value for empty images without any text. When the target is null character and the model correctly predicts null character, CTC loss produce a negative value. Is this the expected behaviour of CTC loss? If so, how should I indicate empty images?
Thanks.
1 Like
I would try to use space instead of blank character, I am assuming you are referring to null as the blank which is a special character to deal with double or triple character problem.
1 Like
I am trying to use CRNN, model to give me Text-Perceptual-Loss, to be used for Text Super Resolution.
I am using pyotrch’s CTC loss,
criterion = nn.CTCLoss(blank=0)
def encode_text_batch(text_batch):
text_batch_targets_lens = [len(text) for text in text_batch]
text_batch_targets_lens = torch.IntTensor(text_batch_targets_lens)
text_batch_concat = "".join(text_batch)
text_batch_targets = []
for c in text_batch_concat:
try:
if (c=='"' ):
id = char2id["'"]
else:
id =char2id[c]
text_batch_targets.append(id)
except:
text_batch_targets.append(0)
text_batch_targets = torch.IntTensor(text_batch_targets)
#print(text_batch_targets)
return text_batch_targets, text_batch_targets_lens
def compute_loss(text_batch, text_batch_logits):
"""
text_batch: list of strings of length equal to batch size
text_batch_logits: Tensor of size([T, batch_size, num_classes])
"""
print(text_batch_logits.shape)
text_batch_logps = F.log_softmax(text_batch_logits, 2) # [T, batch_size, num_classes]
#print(text_batch_logps.shape)
#print(text_batch_logps.size(0))
text_batch_logps_lens = torch.full(size=(text_batch_logps.size(1),),
fill_value=text_batch_logps.size(0),
dtype=torch.int32).to(device) # [batch_size]
#print(text_batch_logps_lens)
#print(text_batch_logps.shape)
#print(text_batch_logps_lens)
text_batch_targets, text_batch_targets_lens = encode_text_batch(text_batch)
#print(text_batch_targets,text_batch_targets_lens)
#print(text_batch_targets_lens)
loss = criterion(text_batch_logps, text_batch_targets, text_batch_logps_lens, text_batch_targets_lens)
return loss
But, like for image-example I am sharing, for “SIT”, if it is predicting SI, loss is less, AS COMPARED TO WHEN IT PREDICTS "SIT
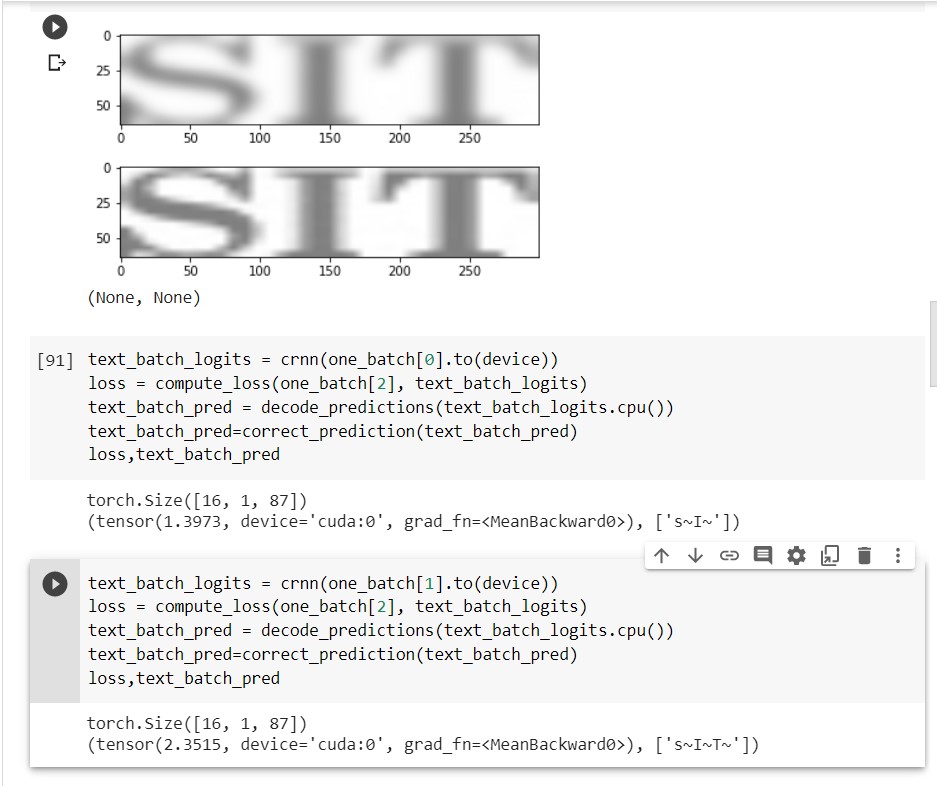
I have faced the same issue and did not get an answer.
As the example of @paarandika was easier to reproduce with the code he offered, I answered there. The gist of it is that you have to be a bit careful about “the prediction” here. CTC loss measures the cumulative probability of all possible alignments. If the individually most probable alignment is matching the targets one, that does not say much about that the sum of all possible alignments is gives a lot of probability mass to the targets. This is particularly true for cases where the predictions are somewhat longer than the target sequences (i.e. you have a lot of ε). Keep in mind that the loss is the negative loss likelihood of the targets under the predictions: A loss of 1.39 means ~25% likelihood for the targets, a loss of 2.35 means ~10% likelihood for the targets. This is very far from what you would expect from, say, a vanilla n-class classification problem, but the universe of alignments is rather large (if you have predictions of sequence length N with C characters (excluding ε), there are sum_{k=1…N}(C^k) >= C^N possible predictions, some of them (hopefully) map to the target sequence (else you get infinite loss, people do ask about this on the forum).
Best regards
Thomas
1 Like