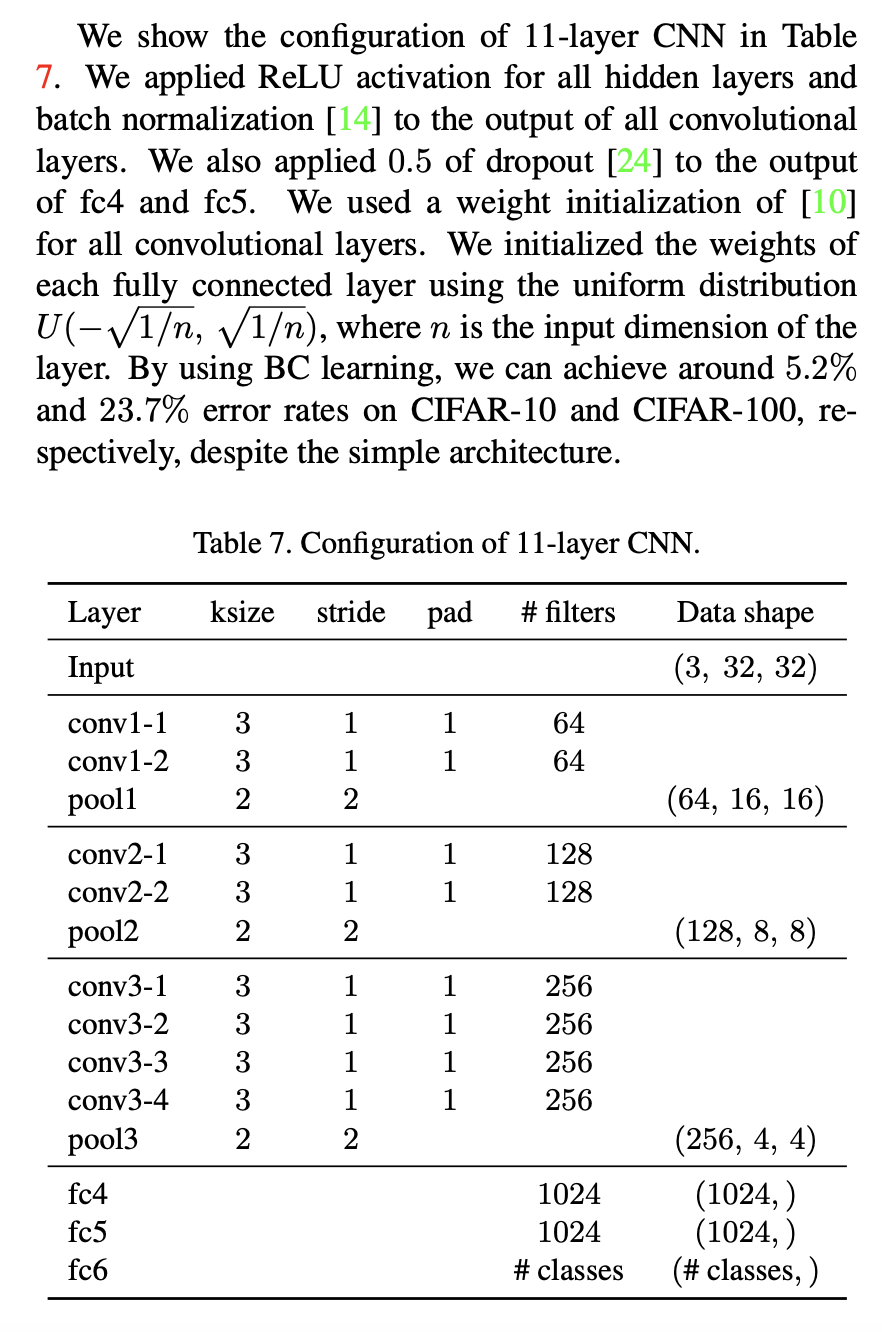
I am pretty new to PyTorch and I am trying to implement BC learning for images as in this paper https://arxiv.org/pdf/1711.10284.pdf
What I’m basically trying to is to mix 2 images and their one-hot encoded labels with a random ratio and then learn the mixing ratio.
My model looks as follows:
class ConvNet(nn.Module):
def __init__(self, n_classes):
super(ConvNet, self).__init__()
self.model = nn.Sequential(OrderedDict([
('conv1', ConvBNReLu(3, 32, 3, padding=1)),
('conv2', ConvBNReLu(32, 32, 3, padding=1)),
('max_pool1', nn.MaxPool2d(2, ceil_mode=True)),
('conv3', ConvBNReLu(32, 64, 3, padding=1)),
('conv4', ConvBNReLu(64, 64, 3, padding=1)),
('max_pool2', nn.MaxPool2d(2, ceil_mode=True)),
('conv5', ConvBNReLu(64, 128, 3, padding=1)),
('conv6', ConvBNReLu(128, 128, 3, padding=1)),
('conv7', ConvBNReLu(128, 128, 3, padding=1)),
('conv8', ConvBNReLu(128, 128, 3, padding=1)),
('max_pool3', nn.MaxPool2d(2, ceil_mode=True)),
('flatten', Flatten()),
('fc4', nn.Linear(in_features=128 * 4 * 4, out_features=512, bias=True)),
('relu5', nn.ReLU()),
('dropout5', nn.Dropout()),
('fc5', nn.Linear(512, 512)),
('relu6', nn.ReLU()),
('dropout6', nn.Dropout()),
('fc6', nn.Linear(512, n_classes)),
('softmax', nn.Softmax(dim=-1))
]))
def forward(self, inp):
return self.model(inp)
Then my learner like this:
criterion = nn.KLDivLoss()
learning_rate = 0.01
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, nesterov=True, weight_decay=5e-4)
scheduler = MultiStepLR(optimizer, milestones=[30, 60, 90], gamma=0.1)
loss_values = []
PATH = './BCplus_epoch10.pth'
for epoch in range(10): # Number of epochs (loops over dataset)
epoch_loss = 0.0
running_loss = 0.0
input = []
labels = []
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
if i % 3 == 2: # batch size of 3 images to ConvNet
input = torch.stack(input) # stack tensors
labels = torch.stack(labels)
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(input)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics every 200 loops
epoch_loss += loss.item() * images_cifar[0][0].size(0)
running_loss += loss.item()
input = [] # clear input
labels = [] # clear labels
images_cifar, labels_cifar = data
images_mix, labels_mix = mix(images_cifar[0], images_cifar[1], labels_cifar[0], labels_cifar[1], training,
True)
input.append(images_mix)
labels.append(labels_mix)
if i % 200 == 199:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
loss_values.append(epoch_loss / 25000) # 25000 images downloaded
print(epoch_loss)
scheduler.step()
And lastly the mixing like this:
def preprocess(image, optplus, train):
if optplus:
normalizer = zero_mean
mean = np.array([4.60, 2.24, -6.84])
std = np.array([55.9, 53.7, 56.5])
else:
normalizer = normalize
mean = np.array([125.3, 123.0, 113.9])
std = np.array([63.0, 62.1, 66.7])
if train:
image = normalize(image, mean, std)
image = horizontal_flip(image)
image = padding(image, 4)
image = random_crop(image, 32)
else:
image = normalize(image, mean, std)
return image
def mix(image1, image2, label1, label2, optplus, train):
image1 = tensor_to_numpy(image1)
image2 = tensor_to_numpy(image2)
image1 = preprocess(image1, optplus, train)
image2 = preprocess(image2, optplus, train)
image1 = torch.from_numpy(image1).float().to(device)
image2 = torch.from_numpy(image2).float().to(device)
label1 = label1.to(device)
label2 = label1.to(device)
# Mix two images
r = torch.rand(1).to(device)
if optplus:
g1 = torch.std(image1).to(device)
g2 = torch.std(image2).to(device)
p = (1.0 / (1 + g1 / g2 * (1 - r) / r)).to(device)
image = ((image1 * p + image2 * (1 - p)) / torch.sqrt(p ** 2 + (1 - p) ** 2)).to(device)
else:
image = (image1 * r + image2 * (1 - r)).to(device)
# Mix two labels
eye = torch.eye(nClasses).to(device)
label = (eye[label1] * r + eye[label2] * (1 - r)).to(device)
return image, label
I am trying to stack 3 images together and then pass them through the model. However when doing this I get a negative loss using KL divergence. I am using this loss function since it is what they use in the paper. Any idea what I am doing incorrectly here?