I’m kind of stuck, and instead of trying to randomly shoot the net with my ideas maybe I can consult it with you (one epoch takes 7h, so I can’t test my random ideas). Here’s the crime scene:
- My objective is to train a VGG-family net on specific custom moderately-large dataset (4.3 mln images, 7205 classes).
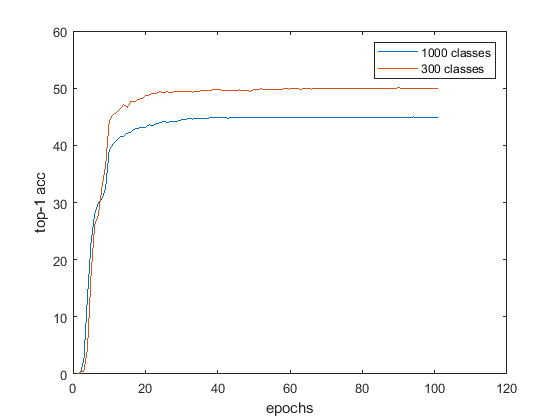
- Since 1 epoch takes 7h to calculate (on whole dataset), I’ve tuned the hyperparameters on 300 classes (approx. 200 000 images). The net gets about 50% top-1 accuracy after 40 epochs, which is ok for me (learning curve attached), and also does pretty good on 1000 (and 2000) classes (on the pic).
- Now I’m prepared for the big heist and I’m training the net on whole dataset. But now the net doesn’t really learn anything, with the accuracy oscillating slightly above random, even after 44 epochs (yep, 13 days of training). Predicted lables of the net are always the same (i.e. 5494, 5494, 5494, 5494, 5494, …) , sometimes after few epochs the prediction change but always for one lable.
- Specs:
- batch size: 64
- learning rate: epochs [0-3]: 0.01, [4-7]: 0.001, [8- …]: 0.0001
- CrossEntrpyLoss with class weightening to prevent overrepresented classes to mess with weights
- optimizer: SGD, momentum=0.9, w/o weight decay
- net trained from scratch
The net architecture and training is exactly the same (except ofc last FC layer which size I’ve changed from 300 to 7205). Do you have any ideas on this? To small FC layers? Wrong learning rate? What Am I missing?