Hi,
I have set the torch.manual_seed(100), and torch.cuda.manual_seed_all(100). I tried re-run the network training again and found that the train loss slightly changes in each epoch (I have confirmed I have the same data shuffle order and data input). Why does this happen? Precision error?
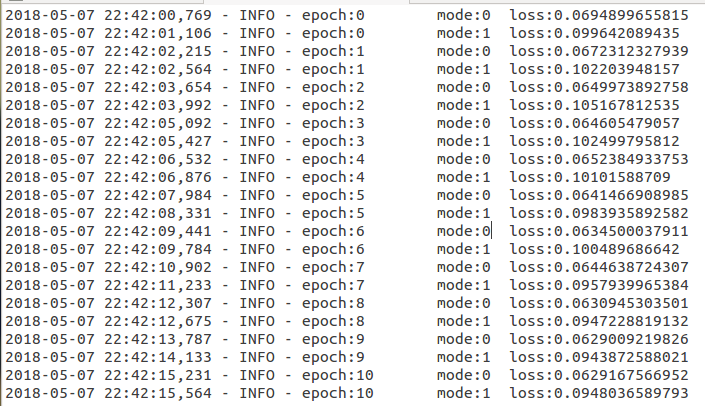
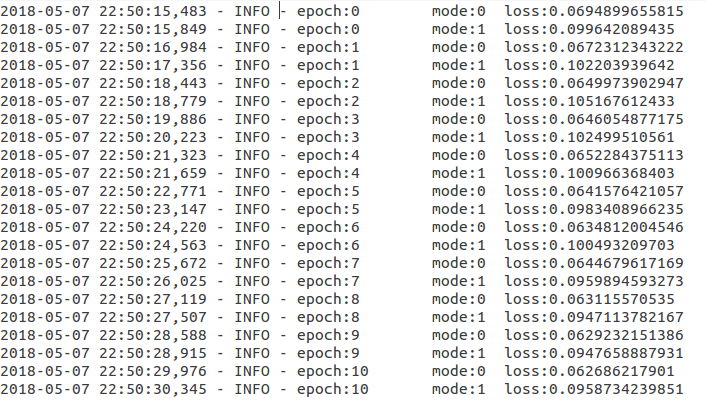
I have uploaded the training and test loss. "mode:0 (training); “mode:1 (test)”. Two images represent two experiments. You can see at first the training loss is the same in 0 epoch in both experiments, but then it gradually differentiate and it is somewhat different at the 10th epoch, ie.g., 0.062917 vs 0.062686.
Thanks!