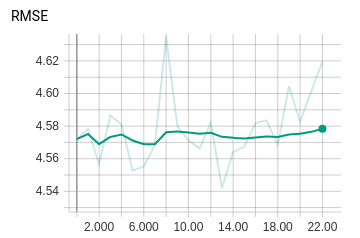
I did a retest where even calling .detach() on the output of model.depthnet results in different RMSE between epochs.
Here are some code snippets. Sorry for the length, I tried to keep it as short as possible!
Edit: I will try to come up with a small executable example but due to used datasets etc. I don’t think small will be easy.
# Data loading code
valid_transform = custom_transforms.Compose([
custom_transforms.Crop(140, 10, 240, 1200),
custom_transforms.Scale(1.05 * output_size[0] / raw_size[0]),
custom_transforms.CenterCrop(output_size),
custom_transforms.ArrayToTensor()
])
val_set = MyDataloader(Path(args.data) / "val", valid_transform, sequence_length=args.sequence_length)
val_loader = torch.utils.data.DataLoader(
val_set, batch_size=1, shuffle=False,
num_workers=args.workers, pin_memory=True)
# Model Loading
depth_net = torch.load("/kitti_resnet34_lvo_split.pth.tar")["model"]
dict_flow_net = torch.load("/PWCNet.pth.tar")
pwcnet = PWCDCNet()
pwcnet.load_state_dict(dict_flow_net)
model = LVONet(depth_net, pwcnet, output_size=output_size)
del dict_flow_net
model = model.cuda()
# Freezing Submodels and building Optimizer
def dfs_freeze(model):
for name, child in model.named_children():
for param in child.parameters():
param.requires_grad = False
dfs_freeze(child)
dfs_freeze(model.depthnet)
dfs_freeze(model.flownet)
cudnn.benchmark = True
print('=> setting adam solver')
optim_params = [
{'params': filter(lambda p: p.requires_grad, model.parameters()), 'lr': args.lr}
]
optimizer = torch.optim.Adam(optim_params,
betas=(args.momentum, args.beta),
weight_decay=args.weight_decay)
#Training
model.train()
for i, (reset, imgs, depth_imgs, intrinsics, intrinsics_inv, scale, pose) in enumerate(train_loader):
torch.cuda.synchronize()
img_list = [img.to(device) for img in imgs]
target_depth = depth_imgs[-1].to(device).float()
imgs = torch.cat([img.unsqueeze(2) for img in img_list], dim=2)
scale = scale.view(scale.shape[0], 1, 1, 1).float().cuda()
intrinsics = intrinsics.to(device).float()
intrinsics_inv = intrinsics_inv.to(device).float()
# compute output
depth2, flow12, exp_masks2, pose21 = model(imgs)
result = Result()
result.evaluate(depth2.data, target_depth.data)
photo_loss, exp_loss = photometric_reconstruction_loss(imgs[:, :, -1], imgs[:, :, -2],
intrinsics, intrinsics_inv,
scale * depth2, exp_masks2, pose21,
include_exp_loss=True)
photo_loss *= args.photo_loss_weight
exp_loss *= args.mask_loss_weight
loss = photo_loss + exp_loss
# compute gradient and do Adam step
optimizer.zero_grad()
loss.backward()
optimizer.step()
#Validation
model.eval()
with torch.no_grad():
for i, (reset, imgs, depth_images, intrinsics, intrinsics_inv, scale, pose) in enumerate(val_loader):
img_list = [img.to(device) for img in imgs]
target_depth = depth_images[-1].to(device).float()
imgs = torch.cat([img.unsqueeze(2) for img in img_list], dim=2)
scale = scale.view(scale.shape[0], 1, 1, 1).float().cuda()
intrinsics = intrinsics.to(device).float()
intrinsics_inv = intrinsics_inv.to(device).float()
# compute output
depth2, flow12, exp_mask2, pose21 = model(imgs)
result = Result()
result.evaluate(depth2.data, target_depth.data)
average.update(result, gpu_time, data_time, depth2.size(0))