Dear All,
I am trying to build a network where identical blocks are chained such that the next block uses the output of the previous one. Let me give an example.
- Suppose, my block is a multi-layer perceptron (MLP) with 10 inputs and single output, trained to solve regression problem.
- There are 3 blocks in total.
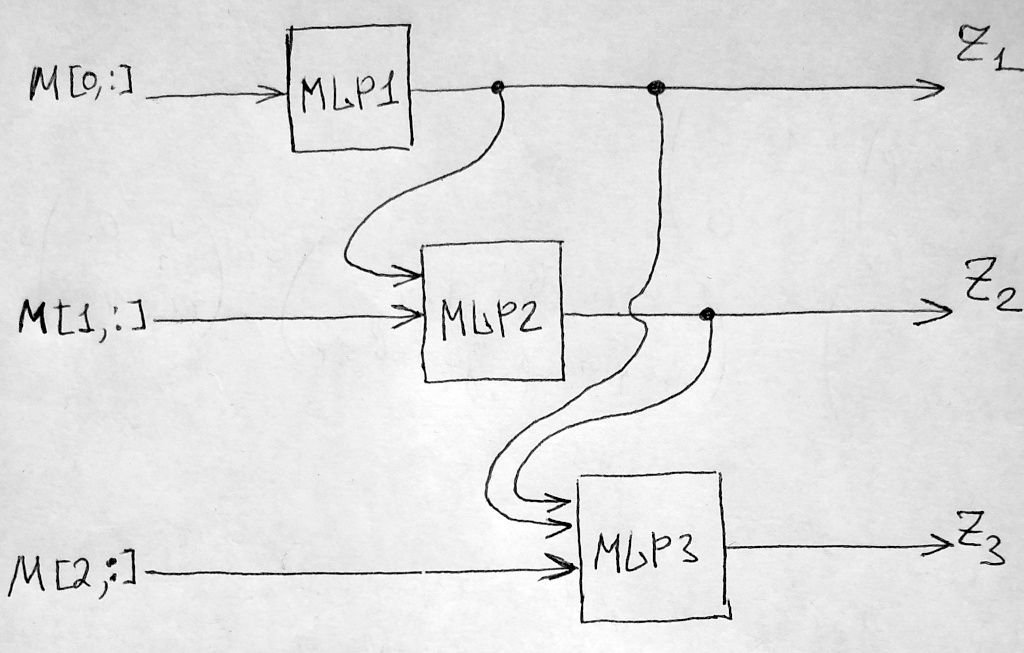
- The input is represented by 3x10 data matrix M.
- The first MLP takes the first row M[0,:] of the data matrix as an input and produces the output z1.
- The second MLP takes the second row M[1,:] except one entry (say, the 1st one). Instead, z1 value is used in place of omitted entry M[1,0]. This second MLP outputs z2.
- The third MLP takes the third row except two entries (say, the 1st and 2nd ones). Instead, z1 and z2 values are used in place of omitted entries M[2,0] and M[2,1]. This third MLP outputs z3.
The architecture could be possibly implemented by means of LSTM network. However, the plan is to use many blocks in training time and just a single MLP block upon testing (prediction). The main requirement here: all MLP blocks must be identical. So, the questions:
- How can I enforce all the blocks to have the same weights and biases during the training optimisation? One possible solution could be as follows: make a single step in gradient descent, then replace weights and biases by their means across all the blocks. How can I implement this procedure? Any better solution?
- How can I connect the outputs of the previous blocks to the inputs of the subsequent ones bypassing certain entries in the input data matrix?
- How can I simultaneously feed the outputs of the blocks into a loss function: Loss = (z1 - y1)**2 + (z2 - y2)**2 + (z3 - y3)**2, where y1, y2, y3 stand for the ground-truth values (labels).
I would greatly appreciate it, if someone kindly gives me a suggestion.