I’m trying to apply a modified alexnet to a compressed sensing task
My training data are grayscale 250x250 input images paired with 10000 element output vectors, stored as jpgs and numpy arrays respectively. Here is the modified alexnet class:
class AlexNet(nn.Module):
def __init__(self,D_out=10000): #added D_out here
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=11, stride=4, padding=2), #changed to 1 channel input image
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, D_out), #changed to D_out=10000 instead of the 1000 categories of vgg
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
I determined to minimize the Euclidean loss with Adam:
model = AlexNet()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
k=30 #size of batch
N = 50 #number epochs
train_loader = DataLoader(train_data, batch_size=k, shuffle=True) #data loader
losses = [] #track the losses
for epoch in range(N):
for i,(inputs,targets) in enumerate(train_loader):
#prepare batch
inputs,targets = Variable(inputs), Variable(targets,requires_grad=False)
#zero gradients
optimizer.zero_grad()
#calculate model prediction
outputs = model(inputs)
#calculate loss
loss = criterion(outputs,targets)
#backpropagate loss
loss.backward()
optimizer.step()
#examine losses
print(loss.data[0])
losses.append(loss.data[0])
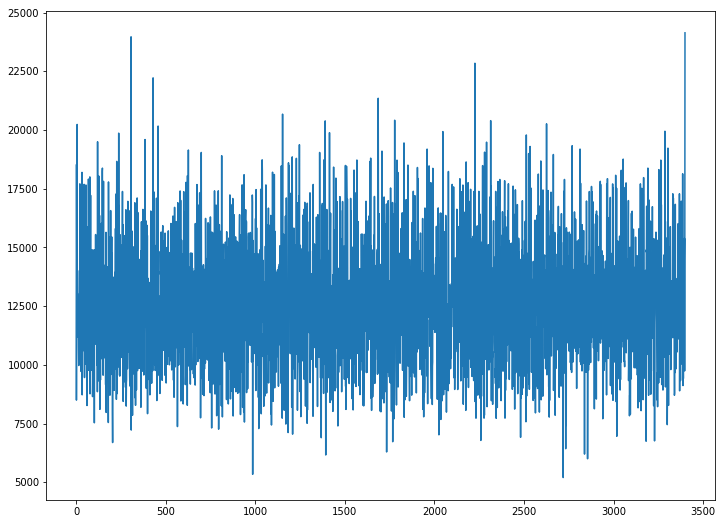
The loss doesn’t decrease. Any suggestions as to why? Any input is appreciated !