If you switch to transformer encoder and have the triangle src_mask, you should be able to predict the next word, just like this example
With just an encoder, wouldn’t the size of the output be limited to the size of src? That is, if I have a sentence the cow jumped over the moon (28 characters), then the maximum length of the predicted title is 28 characters. But with the encoder-decoder, the sentence can be any length and the output can be any length, which I want.
Thanks for your helpful comments here! I am very grateful to see someone who knows what to do. I would like to apply left to right causal attention so that I get a representation for each timepoint in my time series that I can use to make predictions. Do you know of any successful examples of applying this left to right causal attention?
For transformer encoder, the output sequence has same size as the input (a.k.a. src)
Do you think the word language modeling task supports this?
It means the mask attention is still not setup properly. Could you send a code snippet?
I’m still confused with trg_key_paddding_mask. As discribed in the doc, trg_key_paddding_mask’s dimension is (N,S). In translation tasks, the decoder inputs need to mask future words and pad. However, It seems that trg_key_paddding_mask can only masks pad. Does the nn.Transformerdecoder mask the future word in the source code(I have’t found that)?. May be trg_mask (T, T) can mask the future word but it dosen’t work when the input is a batch.
To mask future tokens, you should use src_mask, tgt_mask, memory_mask
Hi, I do not understand why both src and tgt are required for nn.Transformer.
Let’s say for machine translation use case, I understand that during training, src and tgt are 2 different languages. But during testing, given an input, predict an output, we do not have tgt. If so, what should the tgt input? The start of sentence token (e.g. <sos>)?
2 Likes
Yes. The tgt input will be, as you rightly said, <sos>.
Thanks, but src_mask only works when the input is a sequence not batch.
@Jingles From reading the source code of nn.Transformer, it actually does not have an explicit inference making mechanism. I believe the reccommended way is to actually have a for loop that feeds in the tgt inputs auto regressively.
Also, in the case that there was any misunderstanding, the tgt and src are required for teacher forcing in the training phase. tgt should be shift to the right by a <SOS> token.
1 Like
@dav-ell I am having issues with my model learning to copy the previous decoder output aswell. Meaning it gives me something like [ 'h', 'h', 'h', ... ]. For your point on 2. To comment on your process, isn’t this the same as having the tgt_mask instead? Except in tgt_mask case, it actually does this process in parrallel. Did you try this by any chance? At the moment I am using the tgt_mask however no luck! 
Unless I’m missing something it’s a little confusing that the example on how to use nn.Transformer (https://pytorch.org/tutorials/beginner/transformer_tutorial.html) doesn’t use nn.Transformer??
The example explains how to use some of the layers (nn.TransformerEncoder, nn.TransformerEncoderLayer) but it would really help if it covered nn.Transformer itself (in particular the masks and training).
4 Likes
When comparing the loss, in the inner loop, if you have [a,b,c] going to the encoder and [start] to the decoder, we expect the output to be [d]. So in my inner loop, do I compare against the output and see if d was generated?
What’s the difference between a triangle and a square mask?
I am always getting token during inference prediction too. Did you solve the problem? predicted is always .
#
# mostly source: https://pytorch.org/tutorials/beginner/transformer_tutorial.html
with torch.no_grad():
for i, batch in enumerate(val_iter):
src, src_len = batch.src
trg = batch.trg
tgt = torch.zeros((1, 1)).long().cuda() + sos_idx
src, tgt = model.enc_embedding(src).permute(1, 0, 2), model.dec_embedding(tgt).permute(1, 0, 2)
src, tgt = model.enc_pe(src), model.dec_pe(tgt)
memory = model.encoder(src)
tgt = tgt.permute(1, 0, 2)
memory = memory.permute(1, 0, 2)
transformer_out = model.decoder(tgt, memory)
final_out = model.dense(transformer_out)
predicted = F.log_softmax(final_out, dim=-1).argmax(dim=-1)
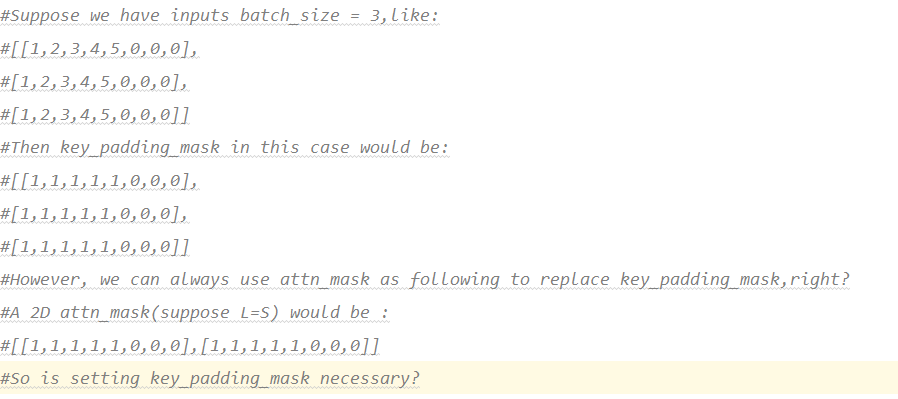
Hi @zhangguanheng66 , I feel a little confused here. Since nn.Transformer is basically using nn.MultiheadAttention, then key_padding_mask and attn_mask in nn.MultiheadAttention seem a little bit redundant to me. Probably, I don’t understand this correct. In nn.MultiheadAttention, key_padding_mask has a shape of (N,S) and attn_mask has a shape of (Nnumheads,L,S),(suppose it is a 3D mask). Doesn’t a (Nnumheads,L,S) attn_mask always simulate a (N,S) key_padding_mask ? In this way, we only need attn_mask, right? Thanks in advance.
1 Like