as mentioned in the title, no grad.data is present in nn.embedding, so how do we train the embeddings?
The weight parameter of nn.Embedding does have this attribute:
emb = nn.Embedding(10, 10)
x = torch.randint(0, 10, (10,))
out = emb(x)
out.mean().backward()
print(emb.weight.grad)
print(emb.weight.grad.data)
However, note that the usage of .data is not recommended.
I Have used the embeddings in a similar fashion, but the weights of embedding layer, before and after have not changed at all.
for epoch in tqdm(range(epochs)):
model.train()
epoch_loss = 0
for batch in tqdm(train_iterator):
src_sentence = Variable(batch['src_sentence']).cuda()
src_speaker = Variable(batch['src_speaker']).cuda()
trg_sentence = Variable(batch['trg_sentence']).cuda()
trg_speaker = Variable(batch['trg_speaker']).cuda()
optimizer.zero_grad()
output, predicted_speaker = model(src_sentence,src_speaker, trg_sentence, trg_speaker)
output = output[1:].view(-1, output.shape[-1])
trg = trg_sentence.permute(1,0)
trg = trg[1:].reshape(-1)
predicted_speaker = log_softmax(predicted_speaker)
loss1 = criterion1(output, trg)
loss2 = criterion2(predicted_speaker, trg_speaker)
loss = loss1 + loss2
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step()
epoch_loss += loss.item()
This is my code for training and computing loss
enc = Encoder(WEIGHTS, HID_DIM, EMB_DIM, PERSONAS, PERSONA_DIM, DROPOUT).cuda()
dec = Decoder(EMB_DIM, PERSONA_DIM, HID_DIM, OUTPUT_DIM, DROPOUT).cuda()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2Seq(enc, dec, len(characters), HID_DIM, device).to(device)
initialization of the model, as you can see i have 3 classes, one for encoder, one for decoder and one for seq2seq.
and inside encoder here is how i have used embedding,
class Encoder(nn.Module):
def __init__(self, weights_matrix, hid_dim, emb_dim, personas, persona_dim, dropout):
super().__init__()
self.word_embedding = nn.Embedding.from_pretrained(weights_matrix, freeze = True)
self.rnn = nn.GRU(emb_dim + persona_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
self.persona_embedding = nn.Embedding(personas+10, persona_dim)
def forward(self, src_sentence, src_speaker):
"""
------------------------------------------------------
Encoder for Seq2seq persona embedding creation
Variable ---- Size
src_sentence [batch size, sequence length]
src_speaker [batch size]
embedded_sentence [batch size, sequence length, emb dim]
embedded_speaker [batch size, persona dim]
emb_con [batch size, sequence length, person dim + emb dim]
emb_con(permute) [sequence length, batch size, person dim + emb dim]
hidden [1, batch size, hidden dim]
------------------------------------------------------
"""
embedded_sentence = self.word_embedding(src_sentence)
embedded_speaker = self.dropout(self.persona_embedding(src_speaker))
embedded_speaker = embedded_speaker.unsqueeze(1).repeat(1,embedded_sentence.shape[1], 1)
emb_con = torch.cat((embedded_sentence, embedded_speaker), dim = 2)
emb_con = emb_con.permute(1,0,2)
output, hidden = self.rnn(emb_con)
return hidden
is it possible that torch.cat is breaking the graph and hence embedding is not being trained?
This shouldn’t be the case.
Skimming through your code, I cannot find anything which breaks the graph or detaches the tensors.
Could you try to isolate the issue and post a code to reproduce this behavior?
Isolating the issue is one of the key problems here, as the model being a sequence to sequence network is pretty big, and hence difficult to debug.
class Decoder(nn.Module):
def __init__(self, emb_dim, persona_dim, hid_dim, trg_vocab_size, dropout):
super().__init__()
self.output_dim = trg_vocab_size
self.word_embedding = nn.Embedding.from_pretrained(weights_matrix, freeze = True)
self.rnn = nn.GRU(emb_dim + hid_dim, hid_dim)
self.out = nn.Linear(emb_dim + hid_dim*2, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, hidden, context):
"""
------------------------------------------------------
Decoder for Seq2seq persona embedding creation
Variable ---- Size
x [1, batch size]
embedded [1, batch size, emb dim]
context [1, batch size, hid dim]
emb_con [1, batch size, hid dim + emb dim]
hidden [1, batch size, hid dim]
output [1, batch size, hid dim]
output [batch size, hid dim*2 + emb dim]
prediction [batch size, trg vocab size]
------------------------------------------------------
"""
x = x.unsqueeze(0)
embedded = self.dropout(self.word_embedding(x))
emb_con = torch.cat((embedded, context), dim = 2)
output, hidden = self.rnn(emb_con, hidden)
output = torch.cat((embedded.squeeze(0), output.squeeze(0), context.squeeze(0)), dim = 1)
prediction = self.out(output)
return prediction, hidden
^the decoder part.
class Seq2Seq(nn.Module):
def __init__(self,encoder, decoder, personas, hid_dim , device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
self.fc = nn.Linear(hid_dim, personas+1)
def forward(self, src,src_speaker,trg, trg_speaker, teacher_forcing_ratio = 0.5):
"""
------------------------------------------------------
End-to-end network for Seq2seq persona embedding creation
Variable ---- Size
trg [batch size, sequence length]
src [batch size, sequence length]
outputs [sequence length, batch size, trg vocab size]
hidden [1, batch size, hid dim]
input [batch size]
------------------------------------------------------
"""
batch_size = trg.shape[0]
trg = trg.permute(1,0)
max_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device)
context = self.encoder(src, src_speaker)
hidden = context
input = torch.LongTensor(np.ones(batch_size))
for t in range(1,max_len):
input = Variable(input).cuda()
hidden = Variable(hidden).cuda()
context = Variable(context).cuda()
output, hidden = self.decoder(input, hidden, context)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
persona_out = self.fc(context).squeeze(0)
return outputs, persona_out
^ The main sequence to sequence network
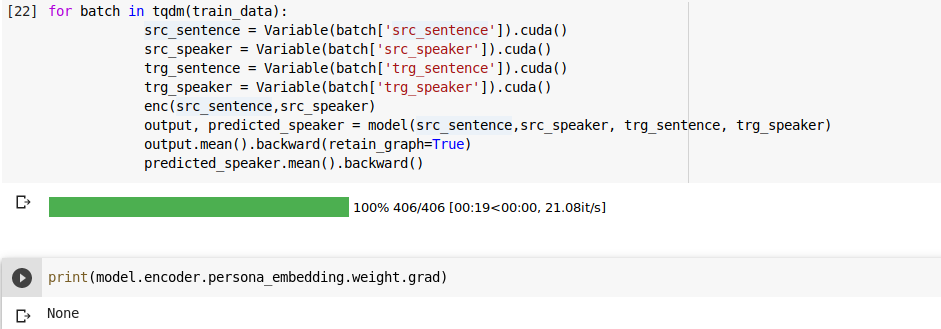
model.encoder.persona_embedding.weight.detach().cpu()
^ I print this before and after training, and it is exactly the same in both the cases.
You are freezing the embedding layer in your initialization:
nn.Embedding.from_pretrained(weights_matrix, freeze = True)
Could you set freeze=False and rerun your code?
If you see in encoder class, there is one nn.embedding without frozen weights, that is where the problem lies, which is not updating.
I don’t know your setup and shapes, but based on this minimal code snippet, the mentioned embedding gets valid gradients:
enc = Encoder(torch.randn(1, 1), 1, 1, 1, 1, 0.0)
dec = Decoder(torch.randn(1, 1), 1, 1, 1, 1, 0.0)
model = Seq2Seq(enc, dec, 1, 1, 'cpu')
src = torch.tensor([[0]]).expand(1, 2)
src_speaker = torch.tensor([0])
trg = torch.tensor([[0]]).expand(1, 2)
trg_speaker = torch.tensor([[0]]).expand(1, 2)
enc(src, src_speaker)
output = model(src, src_speaker, trg, trg_speaker)
output[0].mean().backward(retain_graph=True)
output[1].mean().backward()
print(model.encoder.persona_embedding.weight.grad)
> tensor([[-0.0550],
[ 0.0000],
[ 0.0000],
[ 0.0000],
[ 0.0000],
[ 0.0000],
[ 0.0000],
[ 0.0000],
[ 0.0000],
[ 0.0000],
[ 0.0000]])
But when i only use encoder as a single class, then there is grad present. Its only when i initialize the seq2seq class contiaining the encoder the class, that grad is absent.
class Seq2Seq(nn.Module):
def __init__(self,encoder, decoder, personas, hid_dim , device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
self.fc = nn.Linear(hid_dim, personas+1)
def forward(self, src,src_speaker,trg, trg_speaker, teacher_forcing_ratio = 0.5):
"""
------------------------------------------------------
End-to-end network for Seq2seq persona embedding creation
Variable ---- Size
trg [batch size, sequence length]
src [batch size, sequence length]
outputs [sequence length, batch size, trg vocab size]
hidden [1, batch size, hid dim]
input [batch size]
------------------------------------------------------
"""
batch_size = trg.shape[0]
trg = trg.permute(1,0)
max_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device)
context = self.encoder(src, src_speaker)
# hidden = context
# input = torch.LongTensor(np.ones(batch_size))
# for t in range(1,max_len):
# input = Variable(input).cuda()
# hidden = Variable(hidden).cuda()
# context = Variable(context).cuda()
# output, hidden = self.decoder(input, hidden, context)
# outputs[t] = output
# teacher_force = random.random() < teacher_forcing_ratio
# top1 = output.argmax(1)
# input = trg[t] if teacher_force else top1
persona_out = self.fc(context).squeeze(0)
return persona_out
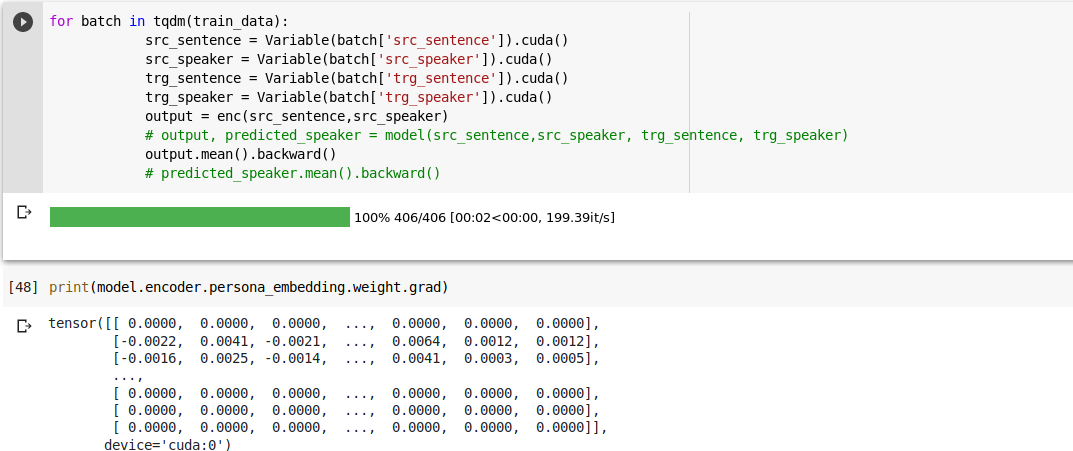
I changed the seq2seq class so that it calls encoder but doesn’t call decoder, then the grad is present.
So i think the problem might be in decoder, or the way i am calling the decoder in seq2seq class.

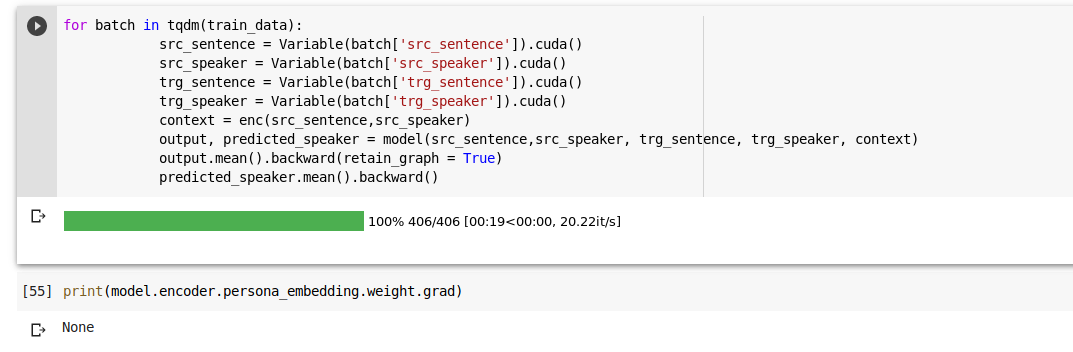
I think I might have solved this, if i keep everything as is and only comment out contex = Variable(context).cuda(), the grad for embedding is present.
I think declaring the output of encoder class as Variable somehow breaks the class, am i correct?
That would be the first time I’m seeing deprecated Variables break the functionality of some code.
And sorry for not mentioning the fact, that I’ve removed them, but I’ve missed it apparently while trying to make the code run.