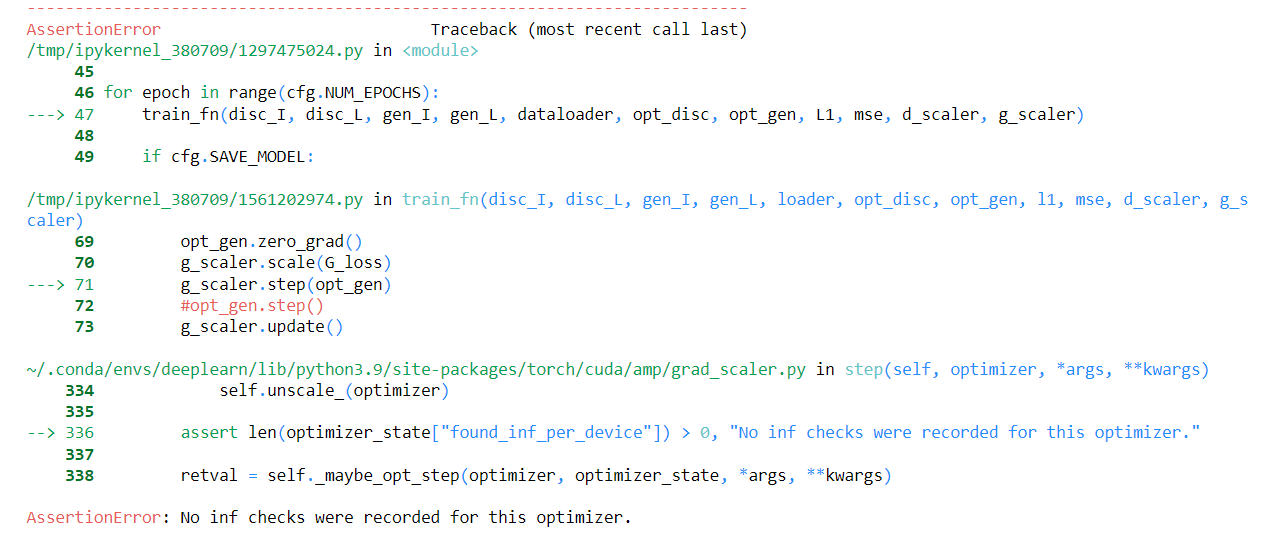
I have been trying to run this code, but I am having always the same problem.
disc_I = Discriminator(in_channel=3).to(cfg.DEVICE1)
disc_L = Discriminator(in_channel=3).to(cfg.DEVICE1)
gen_L = Generator(im_channel=3, num_residuals=9).to(cfg.DEVICE1)
gen_I = Generator(im_channel=3, num_residuals=9).to(cfg.DEVICE1)
opt_disc = torch.optim.Adam(
list(disc_I.parameters()) + list(disc_L.parameters()),
lr=cfg.LEARNING_RATE,
betas=(0.5, 0.999),
)
opt_gen = torch.optim.Adam(
list(gen_I.parameters()) + list(gen_L.parameters()),
lr=cfg.LEARNING_RATE,
betas=(0.5, 0.999),
)
L1 = nn.L1Loss()
mse = nn.MSELoss()
g_scaler = torch.cuda.amp.GradScaler()
# train generator
with torch.cuda.amp.autocast():
# adversarial loss for both generators
D_I_fake = disc_I(fake_initial)
D_L_fake = disc_L(fake_last)
G_I_loss = mse(D_I_fake, torch.ones_like(D_I_fake))
G_L_loss = mse(D_L_fake, torch.ones_like(D_L_fake))
#cycle loss
cycle_last = gen_L(fake_initial)
cycle_initial = gen_I(fake_last)
cycle_last_loss = l1(last, cycle_last)
cycle_initial_loss = l1(initial, cycle_initial)
#identity loss
identity_last = gen_L(last)
identity_initial = gen_I(initial)
identity_last_loss = l1(last, identity_last)
identity_initial_loss = l1(initial, identity_initial)
# add all toghether
G_loss = (G_L_loss + G_I_loss
+ cycle_last_loss*cfg.LAMBDA_CYCLE
+ cycle_initial_loss*cfg.LAMBDA_CYCLE
+ identity_last_loss*cfg.LAMBDA_IDENTITY
+ identity_initial_loss*cfg.LAMBDA_IDENTITY)
opt_gen.zero_grad()
g_scaler.scale(G_loss)
g_scaler.step(opt_gen)
#opt_gen.step()
g_scaler.update()
Where Generator and discriminator are as following.
class Generator(nn.Module):
def __init__(self, im_channel, nfg = 64, num_residuals=9):
super().__init__()
self.initial = nn.Sequential(
nn.Conv2d(im_channel, nfg, kernel_size=7, stride=1, padding=3),
nn.ReLU(inplace=True),
)
self.down_block = nn.ModuleList([
ConvBlock(nfg, nfg*2, kernel_size=3, stride=2, padding=1),
ConvBlock(nfg*2, nfg*4, kernel_size=3, stride=2, padding=1),
])
self.residual_block = nn.Sequential(
*[ResidualBlock(nfg*4) for _ in range(num_residuals)]
)
self.up_block = nn.ModuleList([
ConvBlock(nfg*4, nfg*2, down=False, kernel_size=3, stride=2, padding=1, output_padding=1),
ConvBlock(nfg*2, nfg, down=False, kernel_size=3, stride=2, padding=1, output_padding=1),
])
self.last = nn.Conv2d(nfg, im_channel, kernel_size=7, stride=1, padding=3)
def forward(self, x):
x = self.initial(x)
for layer in self.down_block:
x = layer(x)
x = self.residual_block(x)
for layer in self.up_block:
x = layer(x)
return torch.tanh(self.last(x))
class Discriminator(nn.Module):
def __init__(self, in_channel=3, ngf = 64):
super().__init__()
net = []
net.append(sub_dis(in_channel, ngf, init=True))
ini = ngf
n_layer = 3
for i in range(n_layer):
end = ngf*2
net.append(sub_dis(ini, end, stride=1 if i == n_layer-1 else 2))
ini = end
net.append(nn.Conv2d(ini, 1, kernel_size=4, stride=1, padding=1))
#net.append(nn.Sigmoid())
self.model = nn.Sequential(*net)
def forward(self, x):
return self.model(x)
I could not find any answer on the previous topics that could solve my problem.
Thanks!