Hi mr @ptrblck,
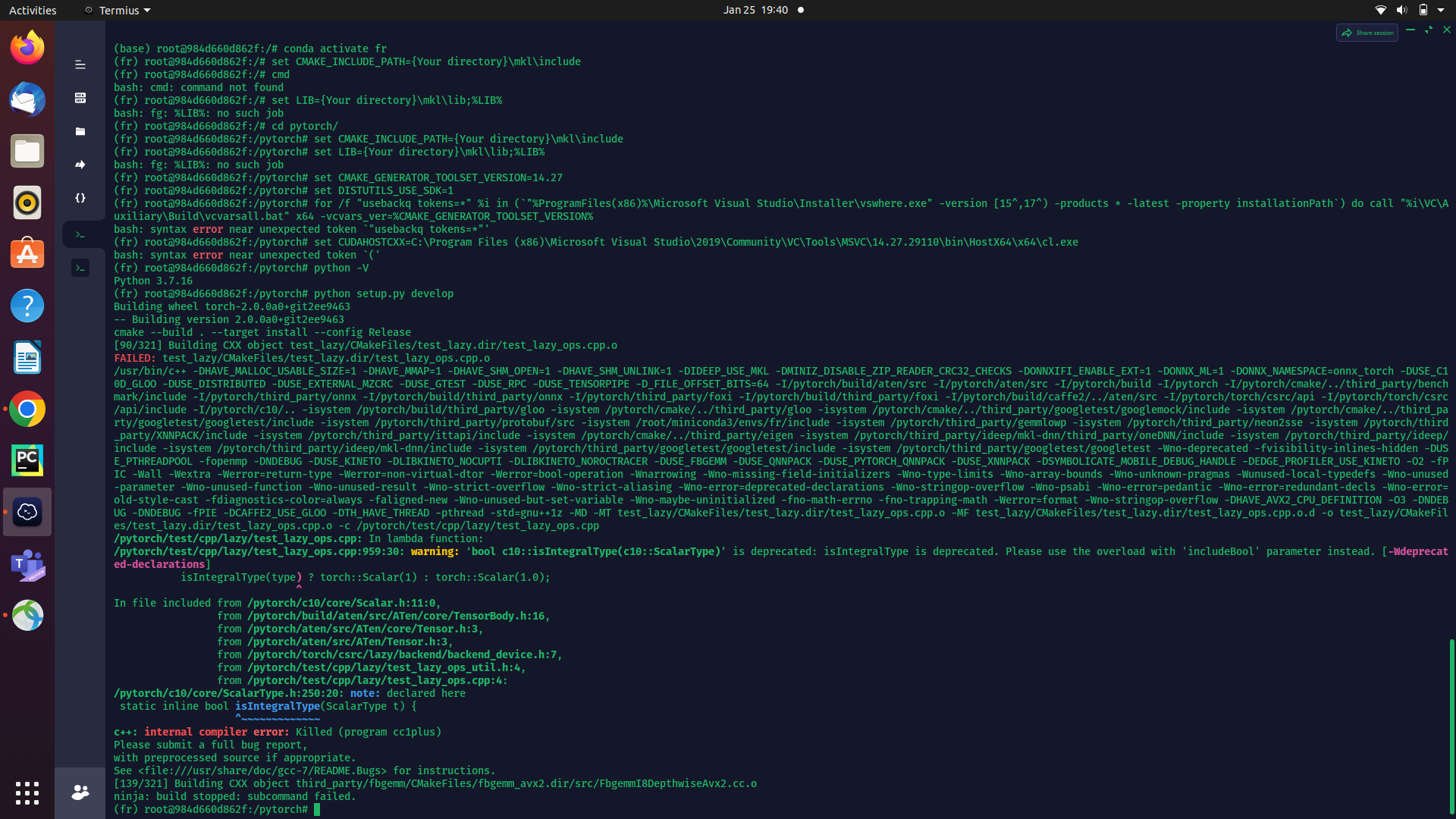
I cannot find the error message, so I am adding the entire result.
Building wheel torch-2.0.0a0+gitd322f82
– Building version 2.0.0a0+gitd322f82
cmake --build . --target install --config Release
[459/874] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp.AVX2.cpp.o
In file included from /usr/include/c++/7/tuple:39:0,
from /usr/include/c++/7/functional:54,
from /pytorch/c10/core/DeviceType.h:10,
from /pytorch/c10/core/Device.h:3,
from /pytorch/build/aten/src/ATen/core/TensorBody.h:11,
from /pytorch/aten/src/ATen/core/Tensor.h:3,
from /pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:2,
from /pytorch/build/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp.AVX2.cpp:1:
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp: In instantiation of ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()>::<lambda(int64_t, int64_t)> [with bool ReLUFused = false; int64_t = long int]’:
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = false]::<lambda(int64_t, int64_t)>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = false]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = false]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = false]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = false; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::Tensor at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = false; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:4229:1: required from here
/usr/include/c++/7/array:94:12: note: ‘struct std::array<signed char, 32>’ has no user-provided default constructor
struct array
^~~~~
/usr/include/c++/7/array:110:56: note: and the implicitly-defined constructor does not initialize ‘signed char std::array<signed char, 32>::_M_elems [32]’
typename _AT_Type::_Type _M_elems;
^~~~~~~~
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp: In instantiation of ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()>::<lambda(int64_t, int64_t)> [with bool ReLUFused = false; int64_t = long int]’:
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = false]::<lambda(int64_t, int64_t)>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = false]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = false]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = false]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = false; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::Tensor at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = false; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:4229:1: required from here
/usr/include/c++/7/array:94:12: note: ‘struct std::array<unsigned char, 32>’ has no user-provided default constructor
struct array
^~~~~
/usr/include/c++/7/array:110:56: note: and the implicitly-defined constructor does not initialize ‘unsigned char std::array<unsigned char, 32>::_M_elems [32]’
typename _AT_Type::_Type _M_elems;
^~~~~~~~
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp: In instantiation of ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()>::<lambda(int64_t, int64_t)> [with bool ReLUFused = false; int64_t = long int]’:
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = false]::<lambda(int64_t, int64_t)>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = false]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = false]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = false]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = false; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::Tensor at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = false; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:4229:1: required from here
/usr/include/c++/7/array:94:12: note: ‘struct std::array<int, 8>’ has no user-provided default constructor
struct array
^~~~~
/usr/include/c++/7/array:110:56: note: and the implicitly-defined constructor does not initialize ‘int std::array<int, 8>::_M_elems [8]’
typename _AT_Type::_Type _M_elems;
^~~~~~~~
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp: In instantiation of ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()>::<lambda(int64_t, int64_t)> [with bool ReLUFused = true; int64_t = long int]’:
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = true]::<lambda(int64_t, int64_t)>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = true]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = true]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = true]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = true; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::Tensor at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = true; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:4230:1: required from here
/usr/include/c++/7/array:94:12: note: ‘struct std::array<signed char, 32>’ has no user-provided default constructor
struct array
^~~~~
/usr/include/c++/7/array:110:56: note: and the implicitly-defined constructor does not initialize ‘signed char std::array<signed char, 32>::_M_elems [32]’
typename _AT_Type::_Type _M_elems;
^~~~~~~~
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp: In instantiation of ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()>::<lambda(int64_t, int64_t)> [with bool ReLUFused = true; int64_t = long int]’:
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = true]::<lambda(int64_t, int64_t)>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = true]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = true]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = true]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = true; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::Tensor at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = true; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:4230:1: required from here
/usr/include/c++/7/array:94:12: note: ‘struct std::array<unsigned char, 32>’ has no user-provided default constructor
struct array
^~~~~
/usr/include/c++/7/array:110:56: note: and the implicitly-defined constructor does not initialize ‘unsigned char std::array<unsigned char, 32>::_M_elems [32]’
typename _AT_Type::_Type _M_elems;
^~~~~~~~
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp: In instantiation of ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()>::<lambda(int64_t, int64_t)> [with bool ReLUFused = true; int64_t = long int]’:
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = true]::<lambda(int64_t, int64_t)>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()>::<lambda()> [with bool ReLUFused = true]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = true]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t)::<lambda()> [with bool ReLUFused = true]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘struct at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = true; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]::<lambda()>’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:123:3: required from ‘at::Tensor at::native::{anonymous}::qcat_nhwc_kernel(const MaterializedITensorListRef&, int64_t, double, int64_t) [with bool ReLUFused = true; at::MaterializedITensorListRef = std::vector<std::reference_wrapper, std::allocator<std::reference_wrapper > >; int64_t = long int]’
/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:4230:1: required from here
/usr/include/c++/7/array:94:12: note: ‘struct std::array<int, 8>’ has no user-provided default constructor
struct array
^~~~~
/usr/include/c++/7/array:110:56: note: and the implicitly-defined constructor does not initialize ‘int std::array<int, 8>::_M_elems [8]’
typename _AT_Type::_Type _M_elems;
^~~~~~~~
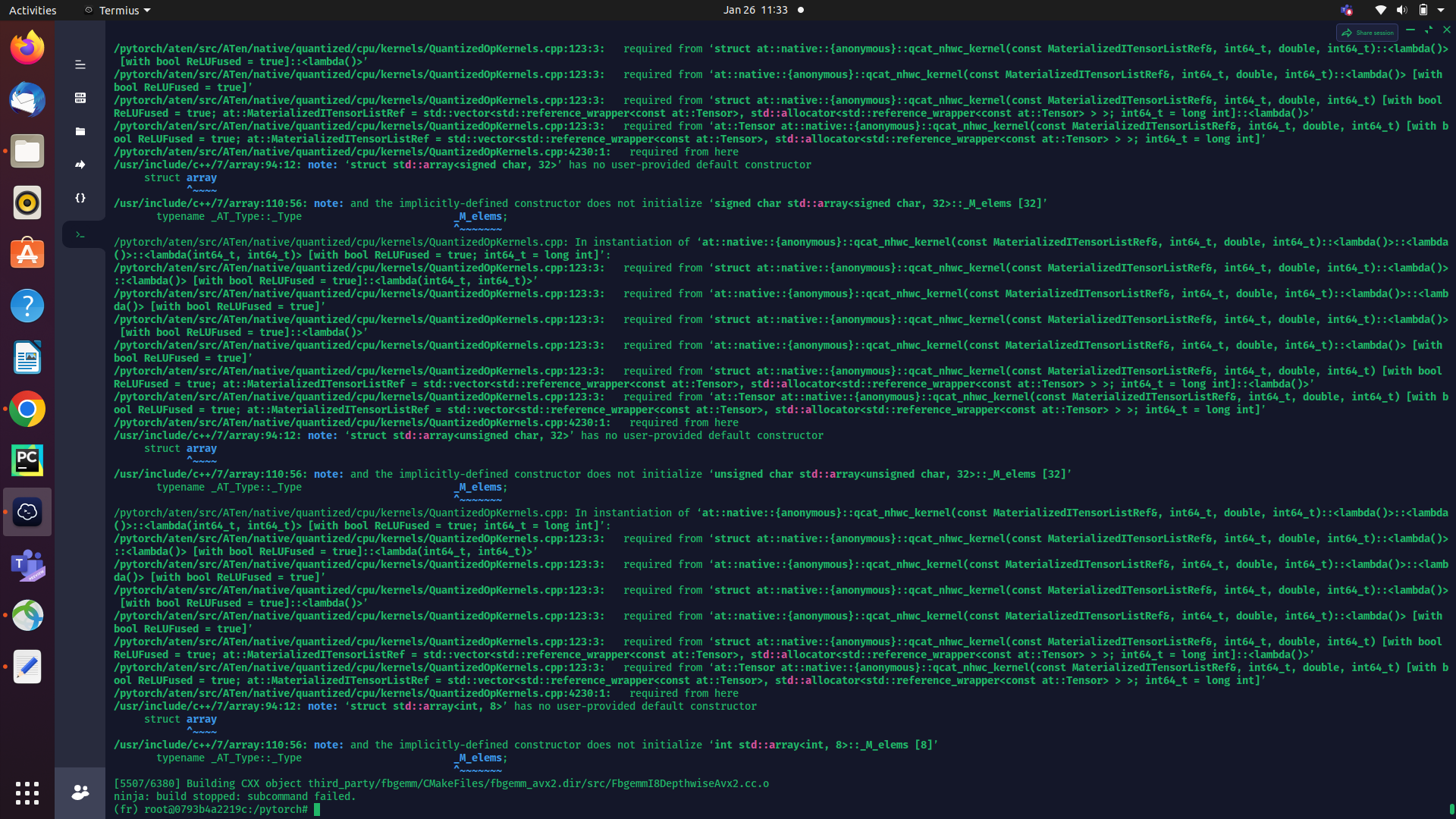
[547/874] Building CXX object test_tensorexpr/CMakeFiles/test_tensorexpr.dir/test_ops.cpp.o
FAILED: test_tensorexpr/CMakeFiles/test_tensorexpr.dir/test_ops.cpp.o
/usr/bin/c++ -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DIDEEP_USE_MKL -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DUSE_C10D_GLOO -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_GTEST -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -I/pytorch/build/aten/src -I/pytorch/aten/src -I/pytorch/build -I/pytorch -I/pytorch/cmake/…/third_party/benchmark/include -I/pytorch/third_party/onnx -I/pytorch/build/third_party/onnx -I/pytorch/third_party/foxi -I/pytorch/build/third_party/foxi -I/pytorch/build/caffe2/…/aten/src -I/pytorch/torch/csrc/api -I/pytorch/torch/csrc/api/include -I/pytorch/c10/… -I/pytorch/third_party/pthreadpool/include -isystem /pytorch/build/third_party/gloo -isystem /pytorch/cmake/…/third_party/gloo -isystem /pytorch/cmake/…/third_party/googletest/googlemock/include -isystem /pytorch/cmake/…/third_party/googletest/googletest/include -isystem /pytorch/third_party/protobuf/src -isystem /root/miniconda3/envs/fr/include -isystem /pytorch/third_party/gemmlowp -isystem /pytorch/third_party/neon2sse -isystem /pytorch/third_party/XNNPACK/include -isystem /pytorch/third_party/ittapi/include -isystem /pytorch/cmake/…/third_party/eigen -isystem /pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/include -isystem /pytorch/third_party/ideep/include -isystem /pytorch/third_party/ideep/mkl-dnn/include -isystem /pytorch/third_party/googletest/googletest/include -isystem /pytorch/third_party/googletest/googletest -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Werror=bool-operation -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -fPIE -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -Wno-unused-variable -pthread -std=gnu++1z -MD -MT test_tensorexpr/CMakeFiles/test_tensorexpr.dir/test_ops.cpp.o -MF test_tensorexpr/CMakeFiles/test_tensorexpr.dir/test_ops.cpp.o.d -o test_tensorexpr/CMakeFiles/test_tensorexpr.dir/test_ops.cpp.o -c /pytorch/test/cpp/tensorexpr/test_ops.cpp
c++: internal compiler error: Killed (program cc1plus)
Please submit a full bug report,
with preprocessed source if appropriate.
See <file:///usr/share/doc/gcc-7/README.Bugs> for instructions.