My understanding of how CNN operates in image detection is through the use of kernels that slide through the image to detect features (edges and so on). So a single kernel could potentially be learning to detect an edge no matter where it is in the image. This is great for image recognition problems where an image of a dog shifted to the right or inverted is still an image of a dog. This article states “the features the kernel learns must be general enough to come from any part of the image”. The article also states how using CNN for categorical data where the order in which data is organised is irrelevant can be “disastrous”.
However, there are instances where it is desirable for the algorithm to be location-aware in order to classify better. Take the case of using CNN to train a network that will predict card play in the game of bridge (a version of double-dummy where all cards are laid out open - perfect information, deterministic). At the beginning of the game the cards dealt to the four could look (very unrealistically) something like this.
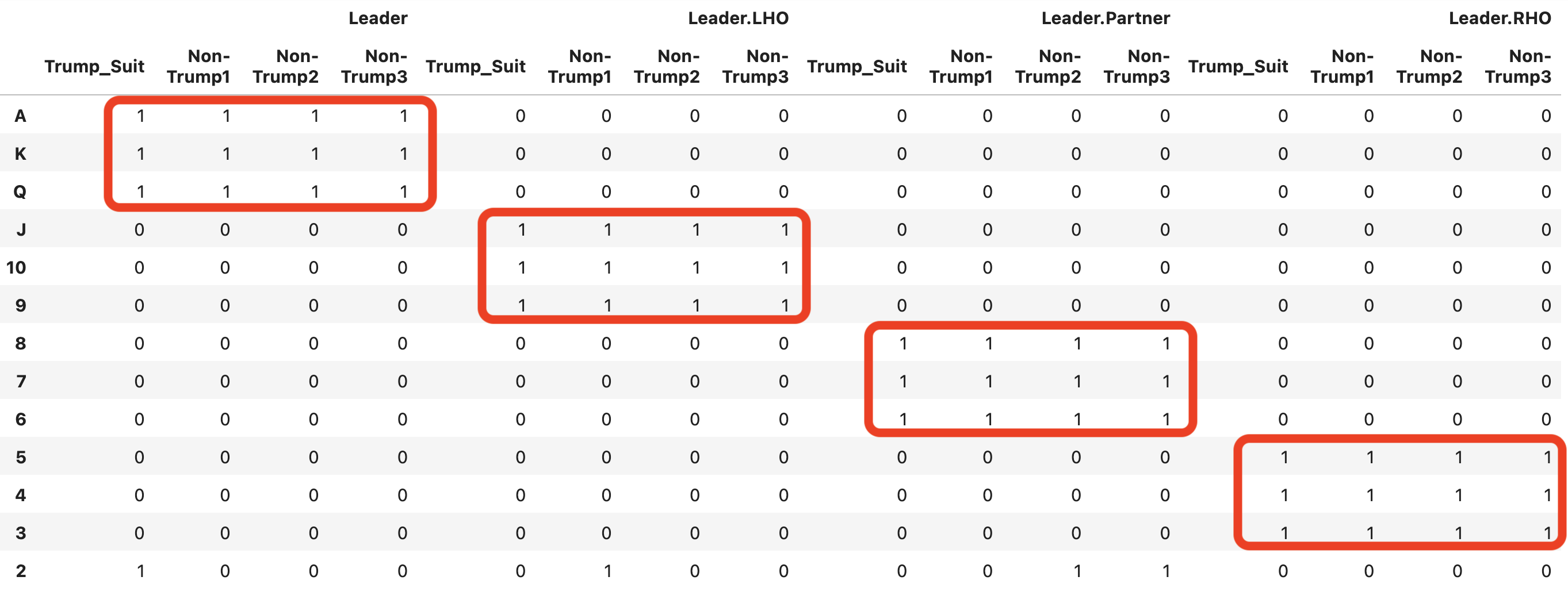
where Leader = the player playing the lead card in round 1, and the subsequent players organised as Leader.LeftHandOpponent, Leader.Partner and Leader.RightHandOpponent. Each player’s cards are organised in four suits starting from the Trump_Suit and then the other suits in the original suit hierarchy. Cards go from highest value in the top ‘A’ to lowest value in the bottom ‘2’.
Here is a transpose of the image above.
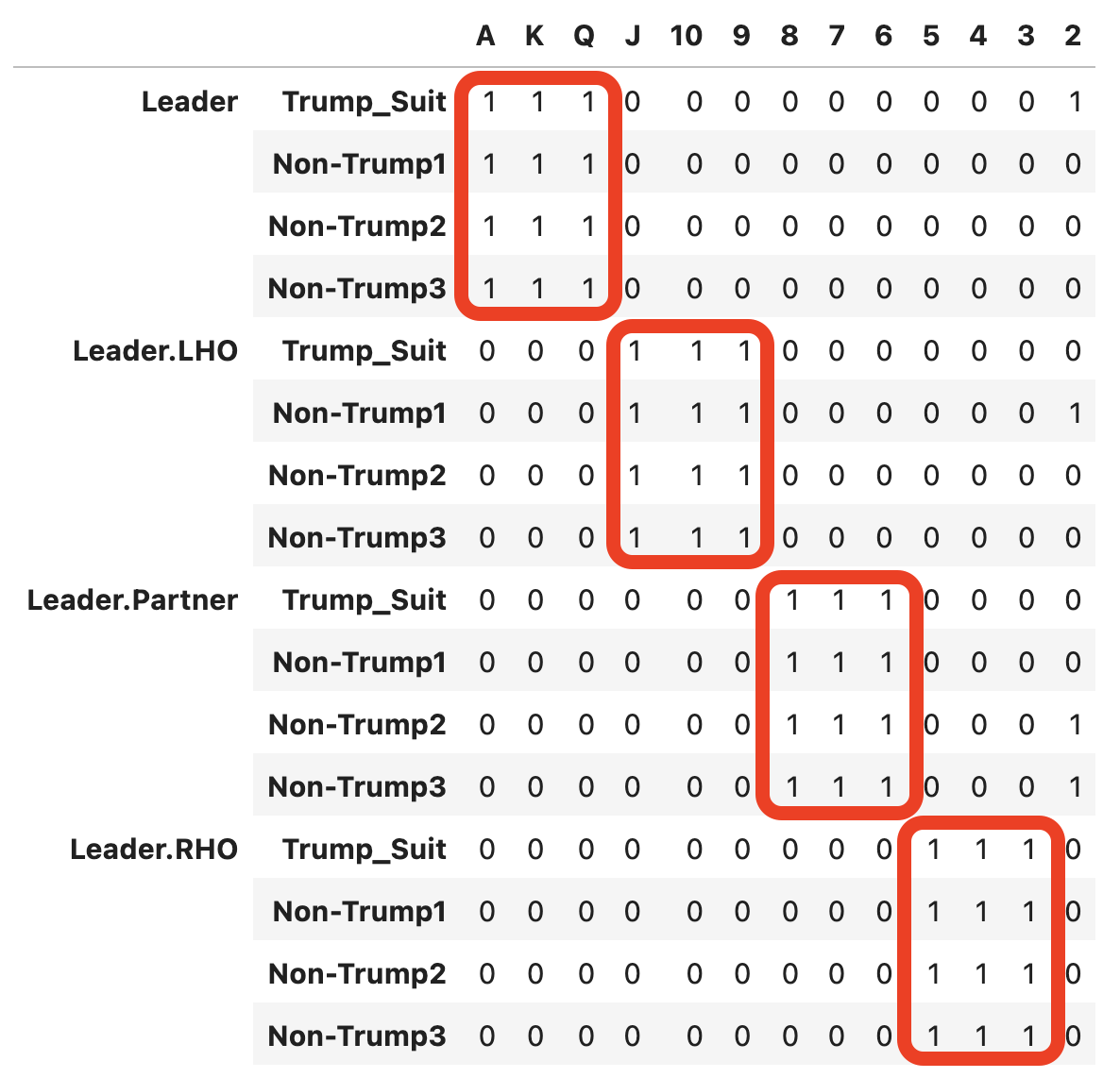
This layout provides a lot of visual cues in terms of how the gameplay will proceed and who will end up winning how many tricks if viewed it from the perspective of control cards distribution within each suit and hand strength. So, the answer to the question of will CNN actually be able to process this data to provide good predictions is a resounding Yes (at least to me).
However, here is the problem - A regular CNN with a sliding kernel with a (4, 1) stride and no padding would make no distinction between the red boxes when in reality there is a massive difference between them.
Possible Solution? - A filter consisting of non-sliding kernels/kernels that only slide in one direction (perhaps horizontally or vertically) however would theoretically only seek to learn location-aware features and that could potentially improve accuracy? Just shooting arrow in the sky.
Has this been researched? Has anybody implemented this already? Could this work?
P.S: CNN has been used on AlphaGo Zero was great success. Obviously in the game of Go, patterns located in the top of the board carry the same weight as those located in the bottom. The gameplay does not change if the board is flipped 180 degrees. This however is not the case in the game of contract bridge. I am looking at ideas of how this can be resolved.