I have a question on basic concept. When we launch a distributed data parallel job over n GPUs, how many processes should each GPU have?
I ask this because I notice different patterns while typing nvidia-smi. Sometimes, each GPU has one single PID. And in total, there are n different PIDs. That’s what I would expect.
However, sometimes each GPU has n PIDs, with one PID using actual memory and all other (n-1) using 0 memory. Moreover, all GPUs shares the same PIDs. That’s hard for me to understand. Are the PIDs taking zero memory due to communication?
You’re right that DDP training should use one GPU per process.
Could you give an example nvidia-smi output that indicates the second case that you’ve mentioned? In general, this might happen if memory is allocated or operations are done on a GPU device that is not “assigned” to that process, although if DDP itself, and not the application, is doing this it is likely an issue we should fix. A script to reproduce would also be helpful.
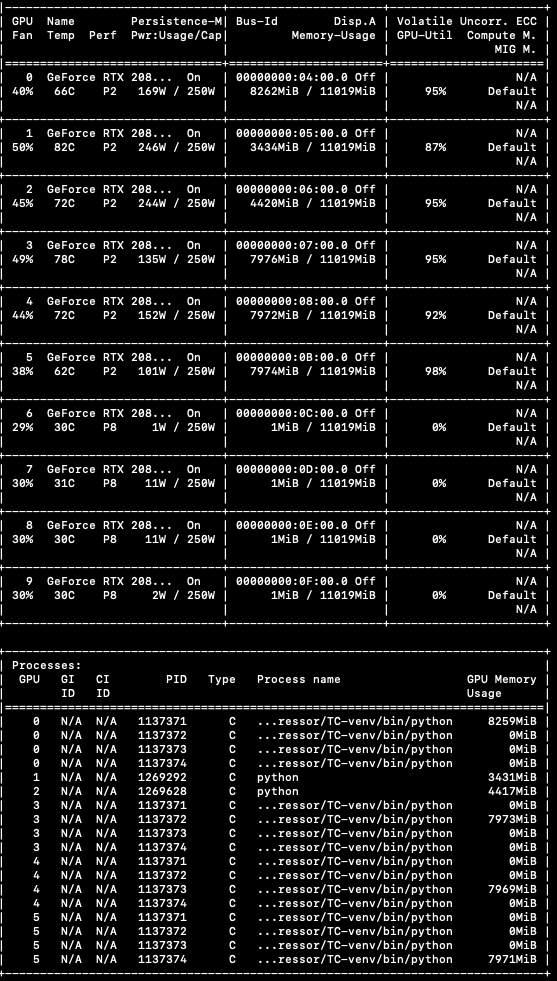
This is a screenshot of nvidia-smi’s output, for the 2nd case. Let me explain a bit. There are 10 GPUs on this node. Someone else is using GPU 1 and 2. GPU 6-9 is not used. I’m using GPU 0, 3, 4, 5, running a DDP job with world_size=4, i.e., n=4.