Hello,
I’m trying to create a Binary class identifier using two pairs of images and I’m running into strange behavior in my attempts to get above 88% validation accuracy. I’m seeing strange periods were loss rapidly increases and the testing set collapses as if it were restarting, but then resumes as if nothing happened.
This is best shown in these two images, particularly in the second:
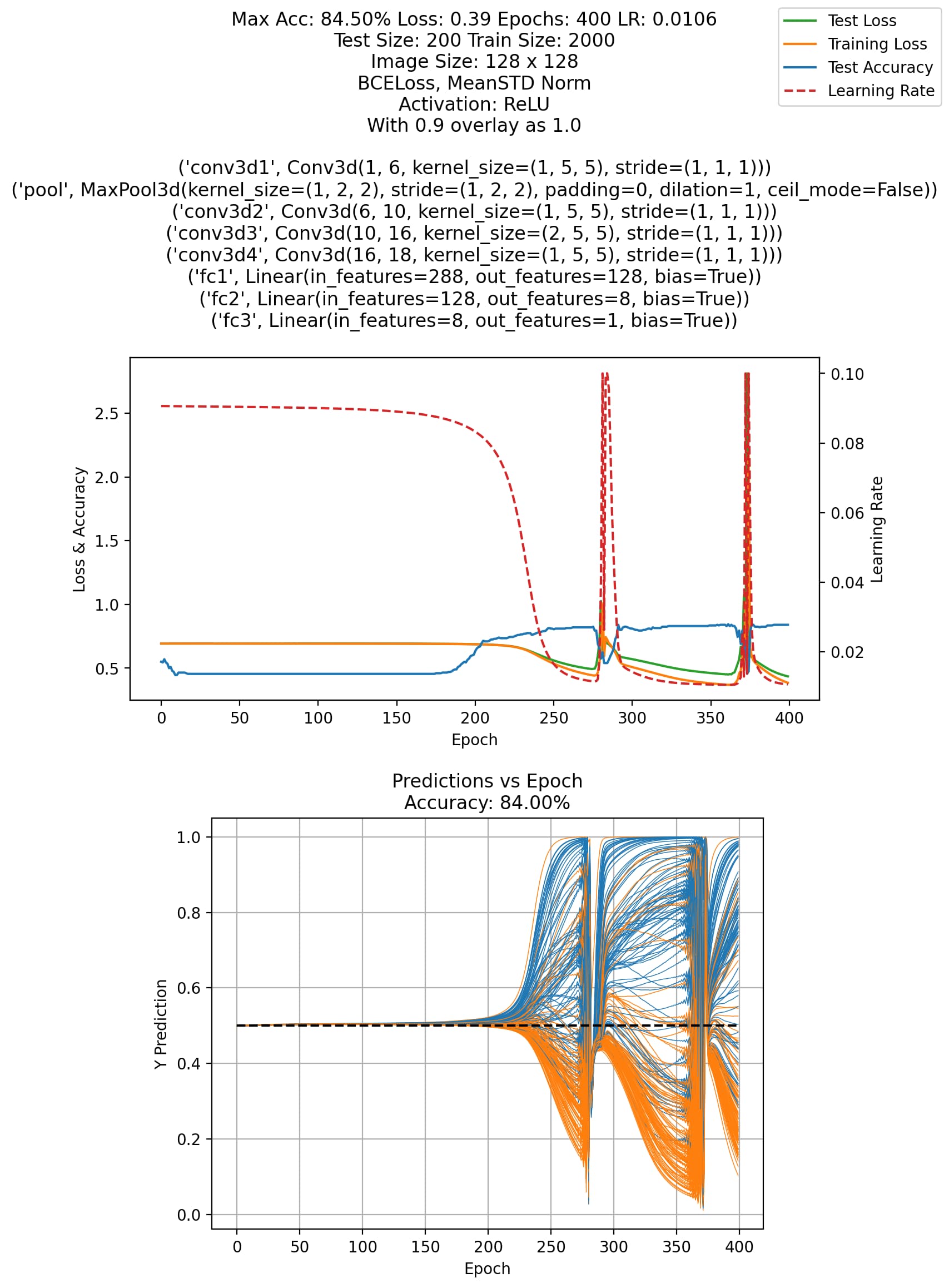
The first image is the standard loss / accuracy plot, whereas the second is the output for each image pair in the validation set vs epoch.
I found that a temporary “fix” to this issue is to adjust the learning rate a as a function of loss, but this feels hacky, not to mention the learning_rate floor has to be quite low to prevent this from happening. The current learning_rate ranges from 0.1 to 0.005. Has anyone else seen something like this before? Is this a sign that the model is bad? Is this a sign of over/underfitting? I’m quite lost on what to do here.
The model I am using is contained in the first chart. Here is my forward pass, loss functions, and training loop:
def forward(self, x):
x = self.conv3d1(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv3d2(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv3d3(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv3d4(x)
x = F.relu(x)
x = self.pool(x)
# Converting data shape from 3 dimensions down to 1 for the linear layers:
x = x.view(-1, x.shape[1] * x.shape[2] * x.shape[3] * x.shape[4])
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
x = torch.sigmoid(x)
return x
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
# a) Forward Pass: Compute Prediction
Y_pred = model(X_train)
loss = criterion(Y_pred, Y_train)
loss_plot_list.append(loss.item())
# b) Backward Pass: Gradients
loss.backward()
# c) Update Weights
optimizer.step()
optimizer.zero_grad()
with torch.no_grad():
[INSERT ACCURACY CALCULATION/PLOTTING HERE]
Let me know if the accuracy section is needed. It’s currently a mess due to the various plotting functions, but accuracy is being calculated by sklearn.metics.accuracy_score()
All help is appreciated and thanks in advance!