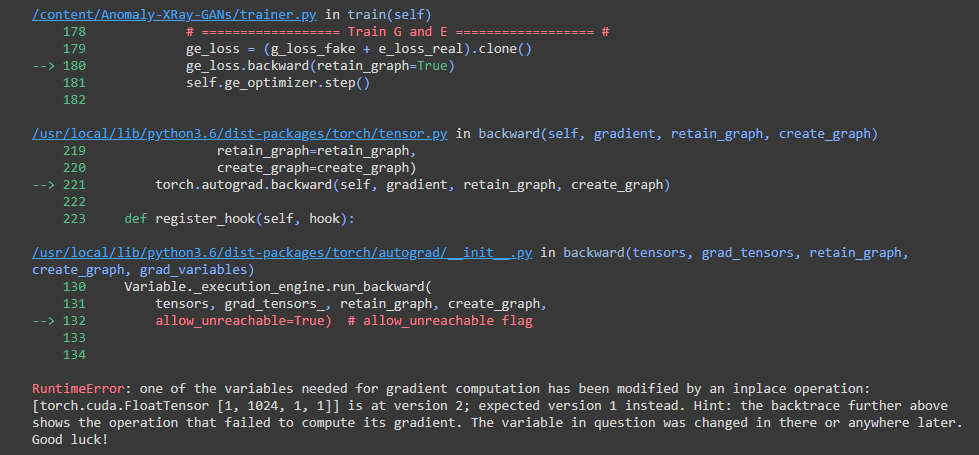
Getting this error
def train(self):
# Data iterator
data_iter = iter(self.data_loader)
step_per_epoch = len(self.data_loader)
model_save_step = int(self.model_save_step * step_per_epoch)
# Fixed input for debugging
fixed_img, _ = next(data_iter)
fixed_z = tensor2var(torch.randn(self.batch_size, self.z_dim))
if self.use_tensorboard:
self.writer.add_image('img/fixed_img', denorm(fixed_img.data), 0)
else:
save_image(denorm(fixed_img.data),
os.path.join(self.sample_path, 'fixed_img.png'))
# Start with trained model
if self.pretrained_model:
start = self.pretrained_model + 1
else:
start = 0
self.D.train()
self.E.train()
self.G.train()
# Start time
start_time = time.time()
for step in range(start, self.total_step):
self.reset_grad()
# Sample from data and prior
try:
real_images, _ = next(data_iter)
except:
data_iter = iter(self.data_loader)
real_images, _ = next(data_iter)
real_images = tensor2var(real_images)
fake_z = tensor2var(torch.randn(real_images.size(0), self.z_dim))
noise1 = torch.Tensor(real_images.size()).normal_().cuda()
noise2 = torch.Tensor(real_images.size()).normal_().cuda()
# Sample from condition
real_z, _, _ = self.E(real_images)
fake_images, gf1, gf2 = self.G(fake_z)
dr, dr5, dr4, dr3, drz, dra2, dra1 = self.D(real_images+noise1, real_z)
df, df5, df4, df3, dfz, dfa2, dfa1 = self.D(fake_images+noise2, fake_z)
# Compute loss with real and fake images
# dr1, dr2, df1, df2, gf1, gf2 are attention scores
if self.adv_loss == 'wgan-gp':
d_loss_real = - torch.mean(dr)
d_loss_fake = df.mean()
g_loss_fake = - df.mean()
e_loss_real = - dr.mean()
elif self.adv_loss == 'hinge1':
d_loss_real = torch.nn.ReLU()(1.0 - dr).mean()
d_loss_fake = torch.nn.ReLU()(1.0 + df).mean()
g_loss_fake = - df.mean()
e_loss_real = - dr.mean()
elif self.adv_loss == 'hinge':
d_loss_real = - log(dr).mean()
d_loss_fake = - log(1.0 - df).mean()
g_loss_fake = - log(df).mean()
e_loss_real = - log(1.0 - dr).mean()
elif self.adv_loss == 'inverse':
d_loss_real = - log(1.0 - dr).mean()
d_loss_fake = - log(df).mean()
g_loss_fake = - log(1.0 - df).mean()
e_loss_real = - log(dr).mean()
# ================== Train D ================== #
d_loss = d_loss_real + d_loss_fake
d_loss.backward(retain_graph=True)
self.d_optimizer.step()
if self.adv_loss == 'wgan-gp':
# Compute gradient penalty
alpha = torch.rand(real_images.size(0), 1, 1, 1).cuda().expand_as(real_images)
interpolated = Variable(alpha * real_images.data + (1 - alpha) * fake_images.data, requires_grad=True)
out,_,_ = self.D(interpolated)
grad = torch.autograd.grad(outputs=out,
inputs=interpolated,
grad_outputs=torch.ones(out.size()).cuda(),
retain_graph=True,
create_graph=True,
only_inputs=True)[0]
grad = grad.view(grad.size(0), -1)
grad_l2norm = torch.sqrt(torch.sum(grad ** 2, dim=1))
d_loss_gp = torch.mean((grad_l2norm - 1) ** 2)
# Backward + Optimize
d_loss = self.lambda_gp * d_loss_gp
d_loss.backward()
self.d_optimizer.step()
# ================== Train G and E ================== #
ge_loss = g_loss_fake + e_loss_real
ge_loss.backward()
self.ge_optimizer.step()