Hi, will be glad for some help to solve this issue.
The problem is:
# RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
This is my code:
def train_single_scale(netD, netG, reals, Gs, Zs, in_s, NoiseAmp, opt, centers=None):
real = reals[len(Gs)]
opt.nzx = real.shape[2] # +(opt.ker_size-1)*(opt.num_layer)
opt.nzy = real.shape[3] # +(opt.ker_size-1)*(opt.num_layer)
opt.receptive_field = opt.ker_size + ((opt.ker_size - 1) * (opt.num_layer - 1)) * opt.stride
pad_noise = int(((opt.ker_size - 1) * opt.num_layer) / 2)
pad_image = int(((opt.ker_size - 1) * opt.num_layer) / 2)
if opt.mode == 'animation_train':
opt.nzx = real.shape[2] + (opt.ker_size - 1) * (opt.num_layer)
opt.nzy = real.shape[3] + (opt.ker_size - 1) * (opt.num_layer)
pad_noise = 0
m_noise = nn.ZeroPad2d(int(pad_noise))
m_image = nn.ZeroPad2d(int(pad_image))
alpha = opt.alpha
fixed_noise = functions.generate_noise([opt.nc_z, opt.nzx, opt.nzy], device=opt.device)
z_opt = torch.full(fixed_noise.shape, 0, device=opt.device, dtype=torch.float32)
z_opt = m_noise(z_opt)
# setup optimizer
optimizerD = optim.Adam(netD.parameters(), lr=opt.lr_d, betas=(opt.beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=opt.lr_g, betas=(opt.beta1, 0.999))
schedulerD = torch.optim.lr_scheduler.MultiStepLR(optimizer=optimizerD, milestones=[1600], gamma=opt.gamma)
schedulerG = torch.optim.lr_scheduler.MultiStepLR(optimizer=optimizerG, milestones=[1600], gamma=opt.gamma)
errD2plot = []
errG2plot = []
errG2norecplot = []
errG2recplot = []
D_real2plot = []
D_fake2plot = []
D_penality = []
z_opt2plot = []
for epoch in range(opt.niter):
if (Gs == []) & (opt.mode != 'SR_train'):
z_opt = functions.generate_noise([1, opt.nzx, opt.nzy], device=opt.device)
z_opt = m_noise(z_opt.expand(1, 3, opt.nzx, opt.nzy))
noise_ = functions.generate_noise([1, opt.nzx, opt.nzy], device=opt.device)
noise_ = m_noise(noise_.expand(1, 3, opt.nzx, opt.nzy))
else:
noise_ = functions.generate_noise([opt.nc_z, opt.nzx, opt.nzy], device=opt.device)
noise_ = m_noise(noise_)
############################
# (1) Update D network: maximize D(x) + D(G(z))
###########################
for j in range(opt.Dsteps):
# train with real
netD.zero_grad()
output = netD(real).to(opt.device)
# D_real_map = output.detach()
errD_real = -output.mean() # -a
errD_real.backward(retain_graph=True)
D_x = -errD_real.item()
# train with fake
if (j == 0) & (epoch == 0):
if (Gs == []) & (opt.mode != 'SR_train'):
prev = torch.full([1, opt.nc_z, opt.nzx, opt.nzy], 0, device=opt.device, dtype=torch.float32)
in_s = prev
prev = m_image(prev)
z_prev = torch.full([1, opt.nc_z, opt.nzx, opt.nzy], 0, device=opt.device, dtype=torch.float32)
z_prev = m_noise(z_prev)
opt.noise_amp = 1
elif opt.mode == 'SR_train':
z_prev = in_s
criterion = nn.MSELoss()
RMSE = torch.sqrt(criterion(real, z_prev))
opt.noise_amp = opt.noise_amp_init * RMSE
z_prev = m_image(z_prev)
prev = z_prev
else:
prev = draw_concat(Gs, Zs, reals, NoiseAmp, in_s, 'rand', m_noise, m_image, opt)
prev = m_image(prev)
z_prev = draw_concat(Gs, Zs, reals, NoiseAmp, in_s, 'rec', m_noise, m_image, opt)
criterion = nn.MSELoss()
RMSE = torch.sqrt(criterion(real, z_prev))
opt.noise_amp = opt.noise_amp_init * RMSE
z_prev = m_image(z_prev)
else:
prev = draw_concat(Gs, Zs, reals, NoiseAmp, in_s, 'rand', m_noise, m_image, opt)
prev = m_image(prev)
if opt.mode == 'paint_train':
prev = functions.quant2centers(prev, centers)
plt.imsave('%s/prev.png' % (opt.outf), functions.convert_image_np(prev), vmin=0, vmax=1)
if (Gs == []) & (opt.mode != 'SR_train'):
noise = noise_
else:
noise = opt.noise_amp * noise_ + prev
fake = netG(noise.detach(), prev)
output = netD(fake.detach())
errD_fake = output.mean()
errD_fake.backward(retain_graph=True)
D_G_z = output.mean().item()
gradient_penalty = functions.calc_gradient_penalty(netD, real, fake, opt.lambda_grad, opt.device)
gradient_penalty.backward()
D_penality.append(gradient_penalty)
errD = errD_real + errD_fake + gradient_penalty
optimizerD.step()
errD2plot.append(errD.detach())
############################
# (2) Update G network: maximize D(G(z))
###########################
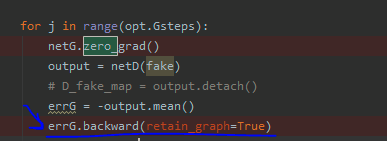
for j in range(opt.Gsteps):
netG.zero_grad()
output = netD(fake)
# D_fake_map = output.detach()
errG = -output.mean()
errG.backward(retain_graph=True)
if alpha != 0:
loss = nn.MSELoss()
if opt.mode == 'paint_train':
z_prev = functions.quant2centers(z_prev, centers)
plt.imsave('%s/z_prev.png' % (opt.outf), functions.convert_image_np(z_prev), vmin=0, vmax=1)
Z_opt = opt.noise_amp * z_opt + z_prev
rec_loss = alpha * loss(netG(Z_opt.detach(), z_prev), real)
rec_loss.backward(retain_graph=True)
rec_loss = rec_loss.detach()
else:
Z_opt = z_opt
rec_loss = 0
optimizerG.step()
errG2norecplot.append(errG.detach())
errG2recplot.append(rec_loss)
errG2plot.append(errG.detach() + rec_loss)
D_real2plot.append(D_x)
D_fake2plot.append(D_G_z)
z_opt2plot.append(rec_loss)
if epoch % 25 == 0 or epoch == (opt.niter - 1):
print('scale %d:[%d/%d]' % (len(Gs), epoch, opt.niter))
if epoch % 500 == 0 or epoch == (opt.niter - 1):
plt.imsave('%s/fake_sample.png' % (opt.outf), functions.convert_image_np(fake.detach()), vmin=0, vmax=1)
plt.imsave('%s/G(z_opt).png' % (opt.outf),
functions.convert_image_np(netG(Z_opt.detach(), z_prev).detach()), vmin=0, vmax=1)
# plt.imsave('%s/D_fake.png' % (opt.outf), functions.convert_image_np(D_fake_map))
# plt.imsave('%s/D_real.png' % (opt.outf), functions.convert_image_np(D_real_map))
# plt.imsave('%s/z_opt.png' % (opt.outf), functions.convert_image_np(z_opt.detach()), vmin=0, vmax=1)
# plt.imsave('%s/prev.png' % (opt.outf), functions.convert_image_np(prev), vmin=0, vmax=1)
# plt.imsave('%s/noise.png' % (opt.outf), functions.convert_image_np(noise), vmin=0, vmax=1)
# plt.imsave('%s/z_prev.png' % (opt.outf), functions.convert_image_np(z_prev), vmin=0, vmax=1)
torch.save(z_opt, '%s/z_opt.pth' % (opt.outf))
print('Generator loss:')
plt.plot(list(range(0, len(errG2plot))), errG2plot)
plt.show()
print('Discriminator real loss:')
plt.plot(list(range(0, len(D_real2plot))), D_real2plot)
plt.show()
print('Discriminator fake loss:')
plt.plot(list(range(0, len(D_fake2plot))), D_fake2plot)
plt.show()
schedulerD.step()
schedulerG.step()
functions.save_networks(netG, netD, z_opt, opt)
return z_opt, in_s, netG
here is where the problem:
@albanD, I’ll be grateful.