I’ve been trying to train model to classify surname language with a char-level rnn.
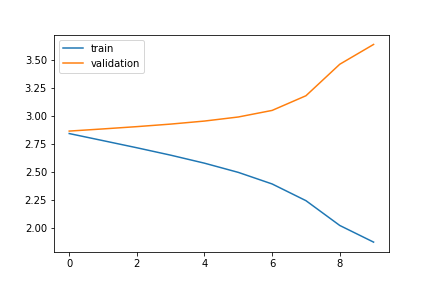
But model during 10 epochs shows almost the same train and validation loss.
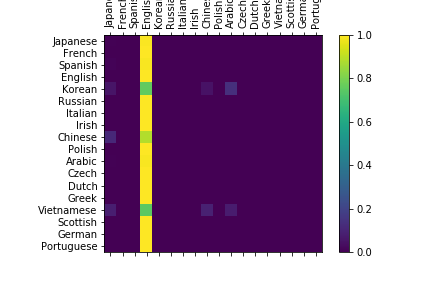
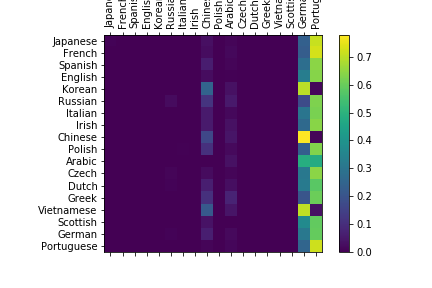
And in confusion matrix all predicts point at only one column.
That’s my notebook on colab.
What am I doing wrong?
Can someone give an advice?
I’ve only had a really quick look at your code - I can have a more in depth look if this suggestion doesn’t work.
Specifically, I’m looking at your train function. It looks as though you’re trying to zero_grad() your model - not your optimizer. My suggestion would be to refactor your train function have:
zero_grad() your optimizer, to avoid accumulating gradients. Usually do this at the start of your training loop.
Actually my notebook is modified version of that nice notebook in which there’s no optimizer and SGD is obtained by manual subtracting of gradients.
This way first we zero our net grads:
rnn.zero_grad()
After that we get output of net and calculate our loss:
loss = criterion(output, category_tensor)
Next we calculate derivatives via backward():
loss.backward()
and finally manual subtracting:
for p in rnn.parameters():
p.data.add_(-learning_rate, p.grad.data)
What I’ve changed in that is that I replace random data point choosing by creating train/validation datasets and add loss output.
But I can’t find the place where I spoil something.
Can you pls take another look at that?
And after every such training I got different confusion matrices which have the same pattern:
only one category was classified for whole dataset (maybe with some noise).
I am not really familiar with RNNs, but looking at your code, I see hidden.detach_(), which removes the variable from the computation graph and therefore may cause your error. Here’s a link that explains what detach() does.
Yes, I did.
But there were no data set splitting into train/valid and data points were chosen by random.
So I only added data splitting.
The most confusing moment is that in confusion matrix is “active” only one category column (screens above) after every next training
The loss difference between training and validation suggests overfitting, which is normal considering that your model seems to always be predicting the same class, as shown in the confusion matrix.
I’m afraid I can’t be of more help, but I would try to find where your model and the one from the tutorial diverge (check if the variable hidden is similar in both cases).