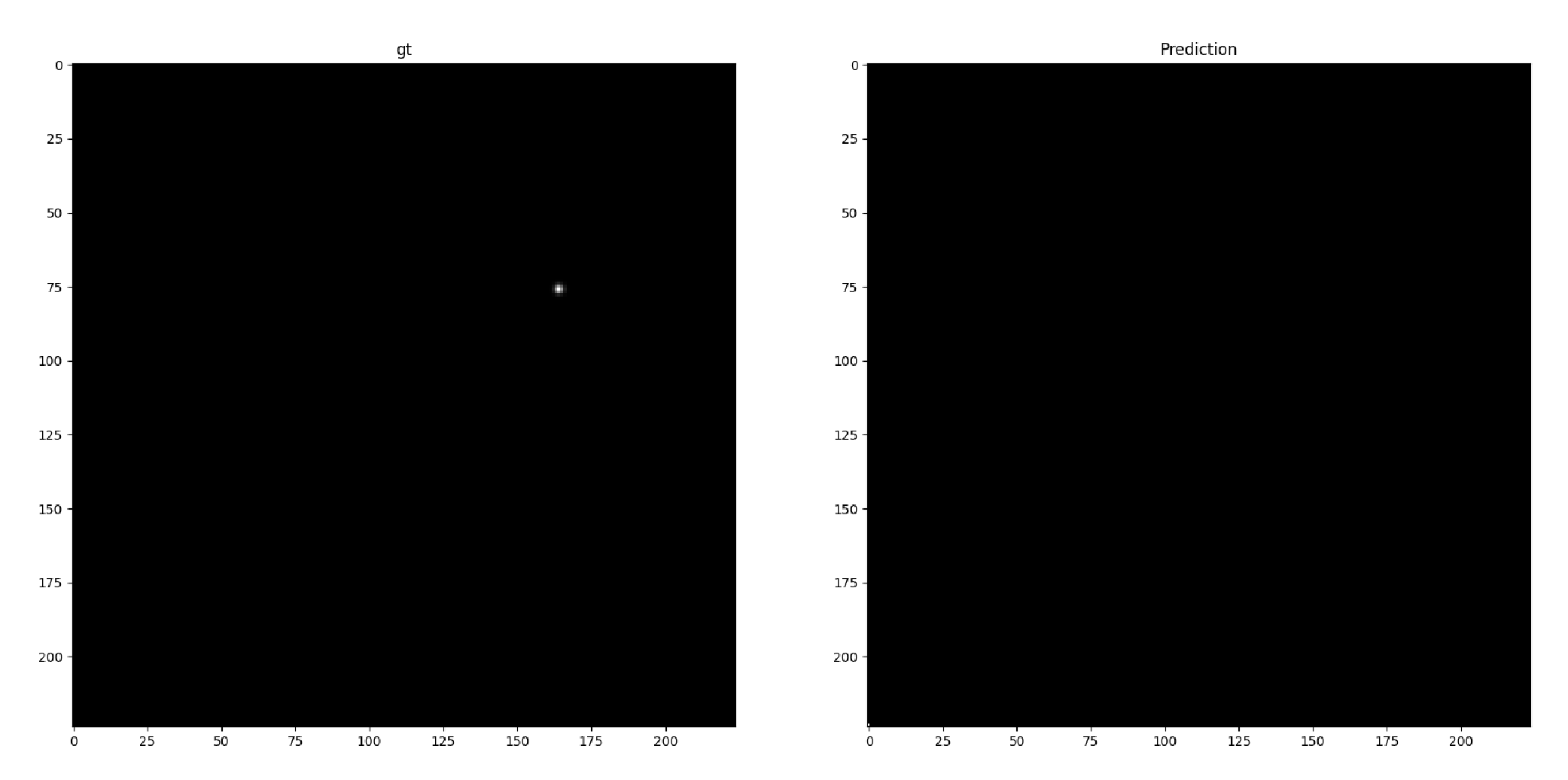
Hi everyone,
I am trying to implement a keypoint detector for radio-graphic images. I have read some articles about keypoint detection in persons and the dominant approach was to use a hourglass architecture that outputs a map with one channel for each point. In order to train the model, most references created the ground truth maps by, for each channels (points), placing a Gaussian centered on the point with a small variance (about 1 px). Then MSE as loss is used on training.
I tried to replicate this approach, but my models’s outputs just becomes a tensor of zeros for all channels very rapidly, what is understandably, but the model rapidly converges to this, and then it spends dozens of epochs with no improvement on the loss.
I really cannot figure out what I might be doing wrong.
This is the architecture I am using:
class UConvDown(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=(3, 3),
stride=(1, 1),
*args,
**kargs,
):
super().__init__()
self.conv0 = nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding=1
)
self.conv1 = nn.Conv2d(
out_channels, out_channels, kernel_size, (1, 1), padding=1
)
self.pool = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0)
def forward(self, x):
x = self.conv0(x)
x = F.relu(x)
x = self.conv1(x)
conv = F.relu(x)
pooled = self.pool(conv)
return conv, pooled
class UConvUp(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=(3, 3),
stride=(1, 1),
*args,
**kargs,
):
super().__init__()
self.convt = nn.ConvTranspose2d(
in_channels, out_channels, (2, 2), (2, 2), padding=0
)
self.conv0 = nn.Conv2d(
out_channels * 2, out_channels, kernel_size, (1, 1), padding=1
)
self.conv1 = nn.Conv2d(
out_channels, out_channels, kernel_size, (1, 1), padding=1
)
def forward(self, x, conv):
x = self.convt(x)
x = torch.cat((x, conv), dim=1)
x = self.conv0(x)
x = F.relu(x)
# pad = compute_padding(x.shape, self.kernel_size, (1, 1)))
x = self.conv1(x)
x = F.relu(x)
return x
class SimpleUnet(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = UConvDown(in_channels, 32)
self.conv2 = UConvDown(32, 64)
self.conv3 = UConvDown(64, 128)
self.conv4 = UConvDown(128, 256)
self.conv5 = UConvDown(256, 512)
self.conv6 = UConvUp(512, 256)
self.conv7 = UConvUp(256, 128)
self.conv8 = UConvUp(128, 64)
self.conv9 = UConvUp(64, 32)
self.conv10 = nn.Conv2d(32, out_channels, (1, 1), (1, 1))
def forward(self, x):
conv1, x = self.conv1(x)
conv2, x = self.conv2(x)
conv3, x = self.conv3(x)
conv4, x = self.conv4(x)
conv5, x = self.conv5(x)
x = self.conv6(conv5, conv4)
x = self.conv7(x, conv3)
x = self.conv8(x, conv2)
x = self.conv9(x, conv1)
x = self.conv10(x)
return x
I am using pytorch-lightning to handle the training loop.