Please pardon my pre-deep-learning graduate training. I am trying to understand whether I have a bug, or what the theoretical reason(s) is(are) for the behavior I am seeing (and suggestions for improvements).
I am exploring multiple models and expect to see overfitting as I add more layers, but instead the deep nets just seem to hit a wall:
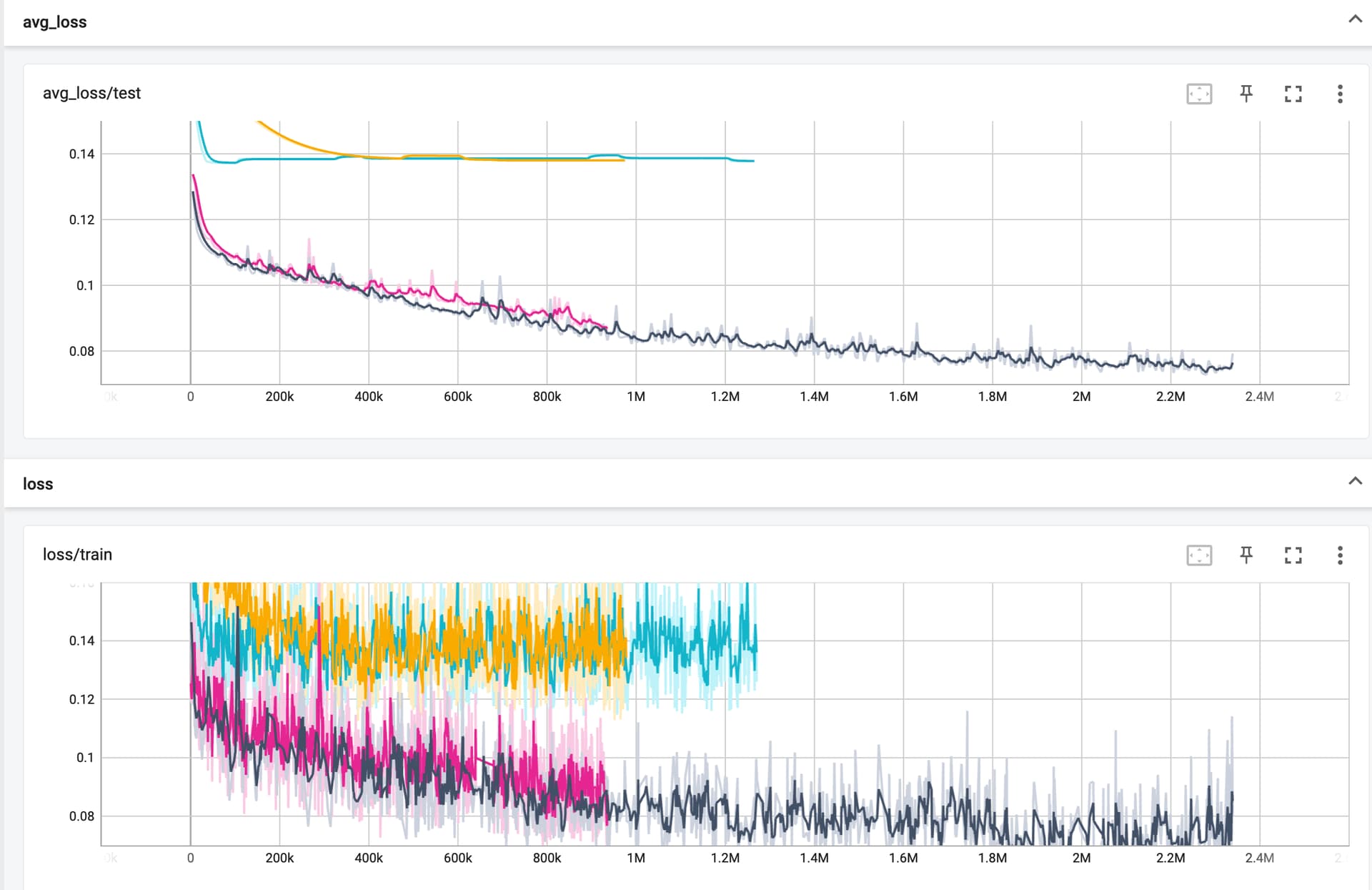
The black trace is the simplest network, defned as:
self.linear_relu_stack = nn.Sequential(
nn.Linear(config["input_dim"], config["input_dim"]),
nn.ReLU(),
nn.Linear(config["input_dim"], config["input_dim"]),
nn.ReLU(),
nn.Linear(config["input_dim"], config["output_dim"]),
)
Some specifics are:
1259837 training samples
139982 test samples
input dimension 9078
output dimension 76
Loss function is MSE, optimizer is SGD.
Outputs are real values, not classes.
The model for the pink trace has one more linear + ReLU pair, while the blue and yellow traces have 11 linear+ReLU layers with learning rates of 0.001 and 0.0001, and trying different physical GPUs.
I’m not understanding why (1) the MSE looks higher overall apparently as a function of the number of layers, and (2) why the deeper nets hit a wall even on the training data.
Why can’t I overfit? Is this to be expected?
Thank you.