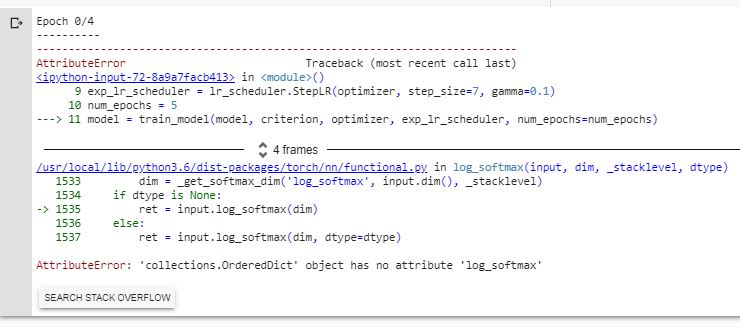
Please i have been trying to train this model (segmentaion_fcn_resnet101) but i kept on getting this error:
And my train_loader and val_loader
if name == ‘main’:
train_dataset = ListDataset('/content/gdrive/My Drive/dataset/Train', 'Train')
train_loader = DataLoader(train_dataset, batch_size=5, shuffle=True, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
val_dataset = ListDataset('/content/gdrive/My Drive/dataset/Validate', 'Validate')
val_loader = DataLoader(dataset=val_dataset, batch_size=5, shuffle=True, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
model = models.segmentation.fcn_resnet101(pretrained= True, aux_loss=None)
for param in model.parameters():
param.requires_grad=False
model.classifier[4] = nn.Conv2d(512, 2, kernel_size=(1, 1), stride=(1, 1))
model.aux_classifier = None
def train_model(model, criterion, optimizer, scheduler, num_epochs=5):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
model.train()
# Each epoch has a training and validation phase
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(True):
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
scheduler.step()
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = running_corrects.double() / len(train_loader.dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
## A Loop for Validation data
model.eval()
for val_inputs, val_labels in val_loader:
val_inputs = val_inputs.to(device)
val_labels = val_labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
with torch.no_grad():
val_outputs = model(val_inputs)
loss = criterion(val_outputs, val_labels)
_, preds = torch.max(val_outputs, 1)
# deep copy the model
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
##Training
for param in model.parameters():
param.requires_grad=False
device = torch.device('cuda’if torch.cuda.is_available() else ‘cpu’)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr = 0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
num_epochs = 5
model = train_model(model, criterion, optimizer, exp_lr_scheduler, num_epochs=num_epochs)
