@tom Thank you for the detailed feedback. I am aware of the negative sampling technique, it was originally used by Collobert + Weston (2008) in their work that was the first fast neural embedding method. (I re-implemented their embedding method and published work on , I changed my username in case you are curious about my work on word embeddings.)
I am not aware of how this would work in the context of a siamese network. Regardless, I have few categories (roughly 5-30 per category, median 10) per embedding. I have about 10 categorical variables. So this is not my issue.
You are right that this is slow.
I did the most naive thing which was decompose the categoricals into dense vectors, each with their own embedding layer with dimension 8:
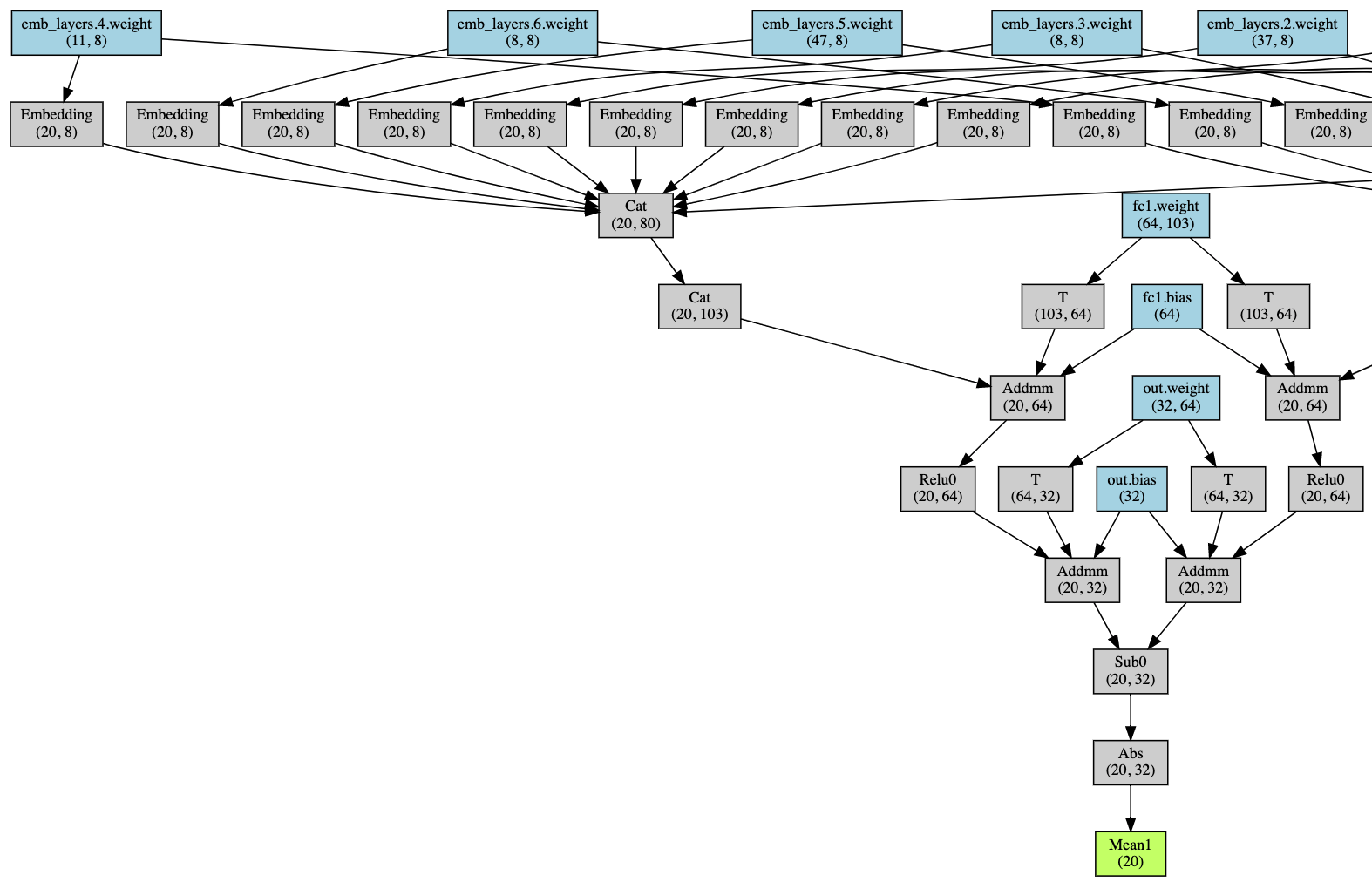
This was about 10x slower with 1000 examples, as I would expect. But with 200K examples, it seems like waaaaay slower, like orders of magnitude, which I did not expect at all. Do you have any idea why? I am currently training on CPU while prototyping, FYI.
[edit: there were some floats in my input categories which exploded the number of classes]
I do understand that rewriting this network to take sparse inputs for the categories would be faster. I want to avoid this because:
If I switch to sparse inputs, then later to pass the output of a softmax into this siamese network for prediction, or moreover to train a joint network with softmax feeding the siamese, I need dense inputs.
p.s. greetings from Berlin