class UNet_down_block(torch.nn.Module):
def __init__(self, input_channel, output_channel, down_size):
super(UNet_down_block, self).__init__()
self.conv1 = torch.nn.Conv2d(input_channel, output_channel, 3, padding=1)
self.bn1 = torch.nn.BatchNorm2d(output_channel)
self.conv2 = torch.nn.Conv2d(output_channel, output_channel, 3, padding=1)
self.bn2 = torch.nn.BatchNorm2d(output_channel)
self.conv3 = torch.nn.Conv2d(output_channel, output_channel, 3, padding=1)
self.bn3 = torch.nn.BatchNorm2d(output_channel)
self.max_pool = torch.nn.MaxPool2d(2, 2)
self.relu = torch.nn.ReLU()
self.down_size = down_size
def forward(self, x):
if self.down_size:
x = self.max_pool(x)
x = self.relu(self.bn1(self.conv1(x)))
x = self.relu(self.bn2(self.conv2(x)))
x = self.relu(self.bn3(self.conv3(x)))
return x
class UNet_up_block(torch.nn.Module):
def __init__(self, prev_channel, input_channel, output_channel):
super(UNet_up_block, self).__init__()
self.up_sampling = torch.nn.Upsample(scale_factor=2, mode='bilinear')
self.conv1 = torch.nn.Conv2d(prev_channel + input_channel, output_channel, 3, padding=1)
self.bn1 = torch.nn.BatchNorm2d(output_channel)
self.conv2 = torch.nn.Conv2d(output_channel, output_channel, 3, padding=1)
self.bn2 = torch.nn.BatchNorm2d(output_channel)
self.conv3 = torch.nn.Conv2d(output_channel, output_channel, 3, padding=1)
self.bn3 = torch.nn.BatchNorm2d(output_channel)
self.relu = torch.nn.ReLU()
def forward(self, prev_feature_map, x):
x = self.up_sampling(x)
x = torch.cat((x, prev_feature_map), dim=1)
x = self.relu(self.bn1(self.conv1(x)))
x = self.relu(self.bn2(self.conv2(x)))
x = self.relu(self.bn3(self.conv3(x)))
return x
class UNet(torch.nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.down_block1 = UNet_down_block(1, 16, False)
self.down_block2 = UNet_down_block(16, 32, True)
self.down_block3 = UNet_down_block(32, 64, True)
self.down_block4 = UNet_down_block(64, 128, True)
self.down_block5 = UNet_down_block(128, 256, True)
self.down_block6 = UNet_down_block(256, 512, True)
self.down_block7 = UNet_down_block(512, 1024, True)
self.mid_conv1 = torch.nn.Conv2d(1024, 1024, 3, padding=1)
self.bn1 = torch.nn.BatchNorm2d(1024)
self.mid_conv2 = torch.nn.Conv2d(1024, 1024, 3, padding=1)
self.bn2 = torch.nn.BatchNorm2d(1024)
self.mid_conv3 = torch.nn.Conv2d(1024, 1024, 3, padding=1)
self.bn3 = torch.nn.BatchNorm2d(1024)
self.up_block1 = UNet_up_block(512, 1024,512)
self.up_block2 = UNet_up_block(256, 512, 256)
self.up_block3 = UNet_up_block(128, 256, 128)
self.up_block4 = UNet_up_block(64, 128, 64)
self.up_block5 = UNet_up_block(32, 64, 32)
self.up_block6 = UNet_up_block(16, 32, 16)
self.last_conv1 = torch.nn.Conv2d(16, 16, 3, padding=1)
self.last_bn = torch.nn.BatchNorm2d(16)
self.last_conv2 = torch.nn.Conv2d(16, 1, 1, padding=0)
self.relu = torch.nn.ReLU()
def forward(self, x):
self.x1 = self.down_block1(x)
self.x2 = self.down_block2(self.x1)
self.x3 = self.down_block3(self.x2)
self.x4 = self.down_block4(self.x3)
self.x5 = self.down_block5(self.x4)
self.x6 = self.down_block6(self.x5)
self.x7 = self.down_block7(self.x6)
self.x7 = self.relu(self.bn1(self.mid_conv1(self.x7)))
self.x7 = self.relu(self.bn2(self.mid_conv2(self.x7)))
self.x7 = self.relu(self.bn3(self.mid_conv3(self.x7)))
x = self.up_block1(self.x6, self.x7)
x = self.up_block2(self.x5, x)
x = self.up_block3(self.x4, x)
x = self.up_block4(self.x3, x)
x = self.up_block5(self.x2, x)
x = self.up_block6(self.x1, x)
x = self.relu(self.last_bn(self.last_conv1(x)))
x = self.last_conv2(x)
return x
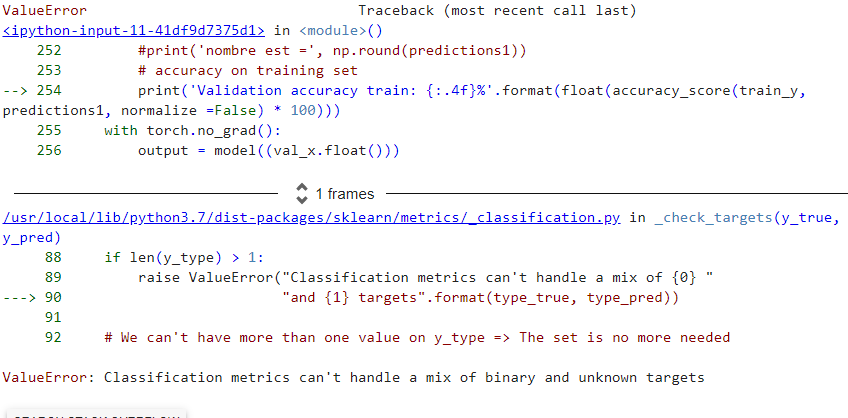
RuntimeError: Given groups=1, weight of size [32, 16, 3, 3], expected input[4592, 1, 10, 10] to have 16 channels, but got 1 channels instead
help me plzzzz