Sorry I’m still not sure what should be modified flr this to work. Why doesn’t it return 2 outputs ?
I stacked my training data and their labels using this line of code to construct the trainloader.
Thank you.
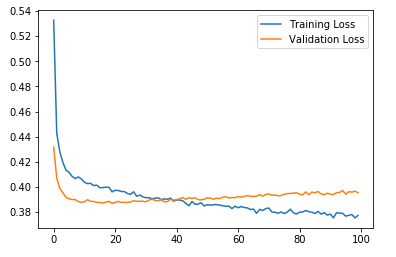
That solves the problem. The network trains but the loss is very high and the accuracy is very low compared to other models trained on the same data set. I think I have a problem with the loss function. If there is any hint or if there is a guide on how to choose the loss function, I would be grateful to have a look at it.
Kind Regards
nn.BCELoss expects a tensor containing probabilities, so you should replace the last F.log_sigmoid in your model with F.sigmoid.
Could you change it and try to fit your data again?
I changed it. The loss is now lower but still the accuracy is too low stuck at 9% compared to 83% with random forest on the same data.
I also tried changing the learning rate to see if it works but still it wiggles around the same accuracy.
I tried different loss functions. I tried changing the learning rate. I tried increasing and decreasing the batch size. But I still have the same problem. The accuracy is too low compared to other models that were used on the same data. It wiggles between 3% to 15% which pretty much random I guess.
You don’t need to use torch.exp, if you’ve used F.sigmoid in your model.
Also, you should use a threshold on the probabilities to get the corresponding class, e.g. 0.5. tensor.topk will return a zero tensor in your current setup.
Do you have a class imbalance in your dataset?
Is the mean of the accuracy increasing for more training epochs are is it stays approx. at the same level?
Yes there is class imbalance 68:32. I tried under-sampling but it didn’t make much of a difference.
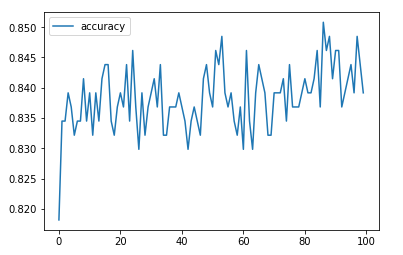
The mean accuracy increases to 84% by the 6th epoch, then bounces back and forth between 79% and 89%.
This happens with very big batch sizes. With small batch size it can even bounce between 75% and 97%.
Thanks for the info.
Are you plotting the accuracy for the whole epoch or for each batch?
Could you check the predictions of your model and see if they (mostly) belong to the majority class?
I’m plotting accuracy for the whole epoch.
Predictions are 73% belonging to majority, but the test labels are 69% belonging to majority. So it’s close to the true values.