I’m training GPT-2 from huggingface/transformers on TPU. It’s training well. At the end of a training I’ve got loss around 4.36. When I save and restore the model - the loss skyrockets somewhere to 9.75.
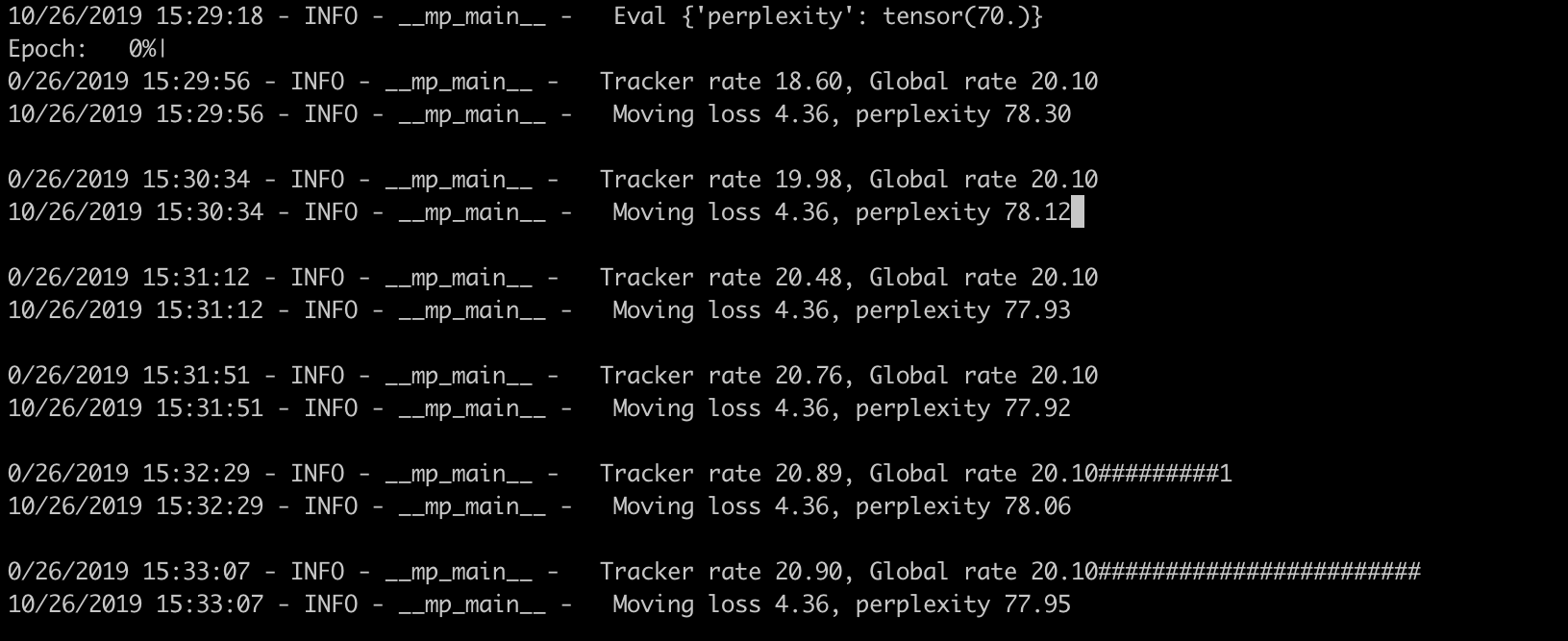

I’ve got no similar issues with saving and loading on GPU with that code.
The code what is used to save is just this
xm.save(model_to_save.state_dict(), output_model_file)
xm.save is a convinience what moves tensors from TPU to CPU before saving.
The whole code is here ru_transformers/tpu_lm_finetuning.py at master · mgrankin/ru_transformers · GitHub
I’ve tried to do the following.
- I’ve tried to do save and load right after the training
results = evaluate(args, model, tokenizer, "checkpoint-0", False)
log_info(f"Eval1 {results}")
model = model_class.from_pretrained(args.model_name_or_path, from_tf=bool('.ckpt' in args.model_name_or_path), config=config)
model.to(args.device)
results = evaluate(args, model, tokenizer, "checkpoint-0", False)
log_info(f"Eval2 {results}")
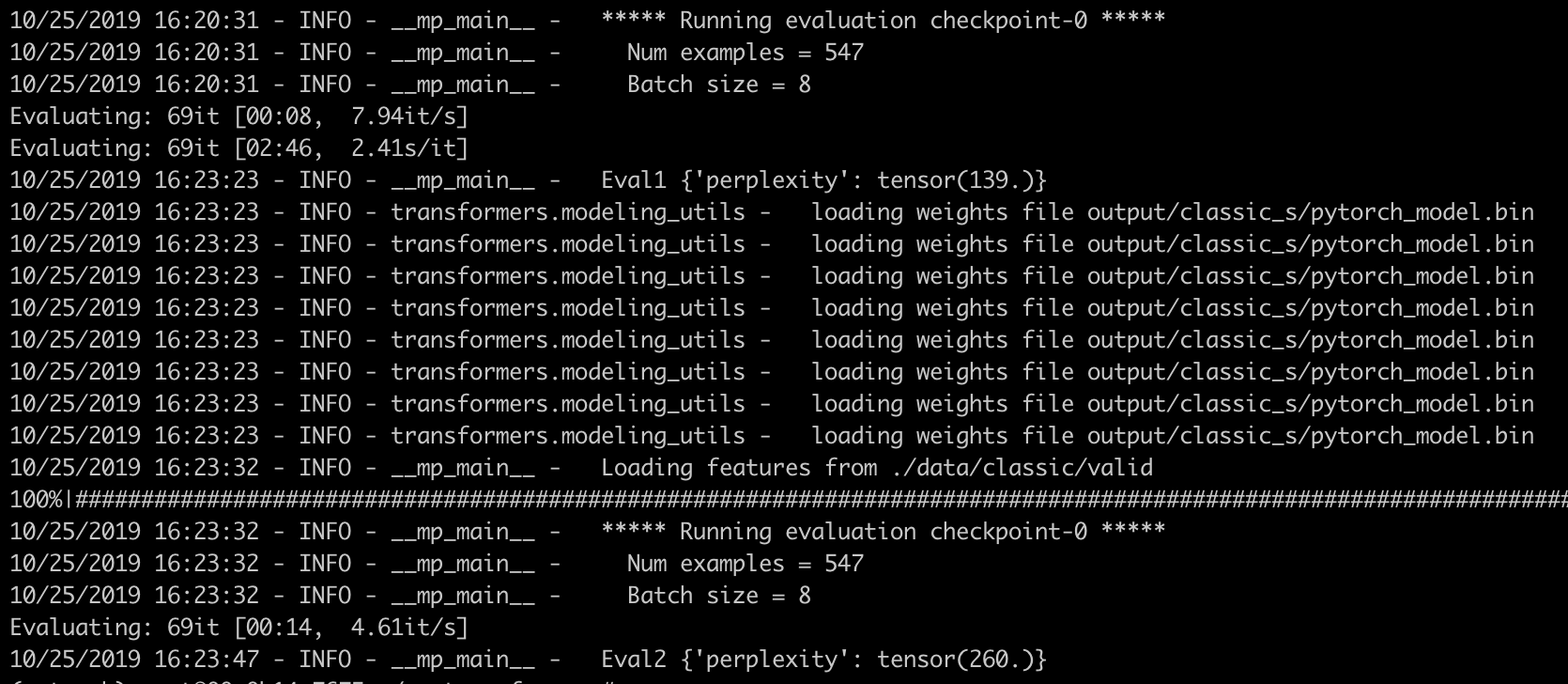
Eval2 is much bigger that Eval1
- I also tried not to recreate the model, but to replace model state_dict with saved state_dict
results = evaluate(args, model, tokenizer, "checkpoint-0", False)
log_info(f"Eval1 {results}")
model.load_state_dict(torch.load('output/classic_s/pytorch_model.bin'))
model.to(args.device)
results = evaluate(args, model, tokenizer, "checkpoint-0", False)
log_info(f"Eval2 {results}")
In that case Eval2 is equal to Eval1
So, there is something that isn’t in a state_dict, but it affects the model perfomance. What can that be?