Hi guys, I am very new to pytorch and torchtext. I am trying to do a stratified sampling before convert the training and test sets to torchtext datasets. Here are my codes:
# stratified sampling
TEXT = data.Field(tokenize = tokenizer, lower=True, include_lengths = True)
LABEL = data.LabelField(dtype = torch.long)
fields = {'reviewText': ('t', TEXT), 'sentiment': ('l', LABEL)}
label = text.sentiment
train_data, valid_data, y_train, y_val = train_test_split(text, label, test_size=0.33, stratify=label)
train_data = train_data.reset_index(drop=True)
train_data.head()
train_dataset = data.Dataset(train_data, fields)
valid_dataset = data.Dataset(valid_data, fields)
#### Vocabulary ###
MAX_VOCAB_SIZE = 25000
#GloVe vocabulary
TEXT.build_vocab(train_dataset,
max_size = MAX_VOCAB_SIZE,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_dataset)
# Check if it worked
print(f'Number of training examples: {len(train_dataset)}')
print(f'Number of testing examples: {len(valid_dataset)}')
print(vars(train_dataset[0]))
Then I got error at the last line when printing the train dataset:

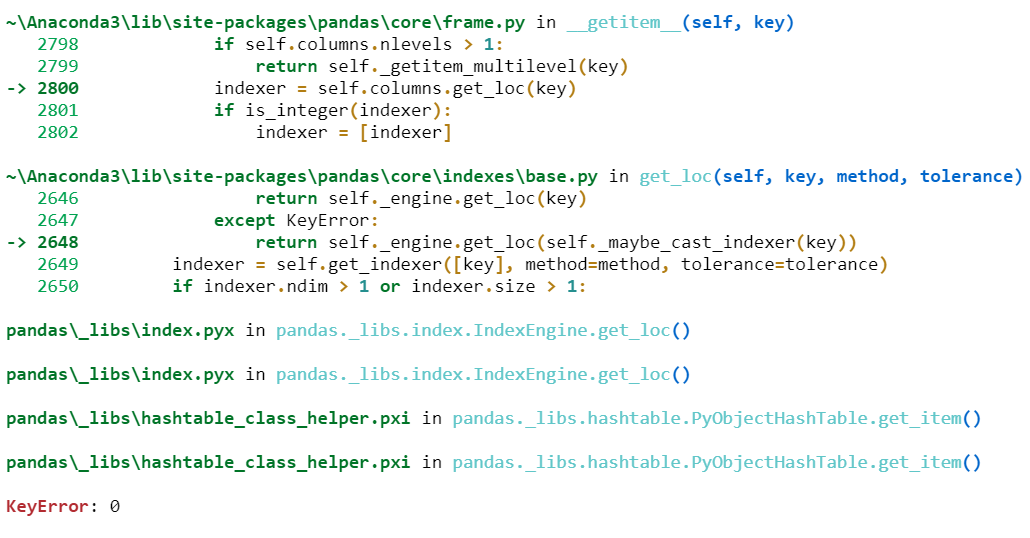
Could anyone help? Many thanks!