With U_t being the input weights at time t and W_t being the recurrent weights at time t. So there are 2 weight matrices that are used in each cell. I am definetely not an expert so maybe wait for a more accurate response.
Hi! I think (I may be wrong) that it is just two ways of saying the same:
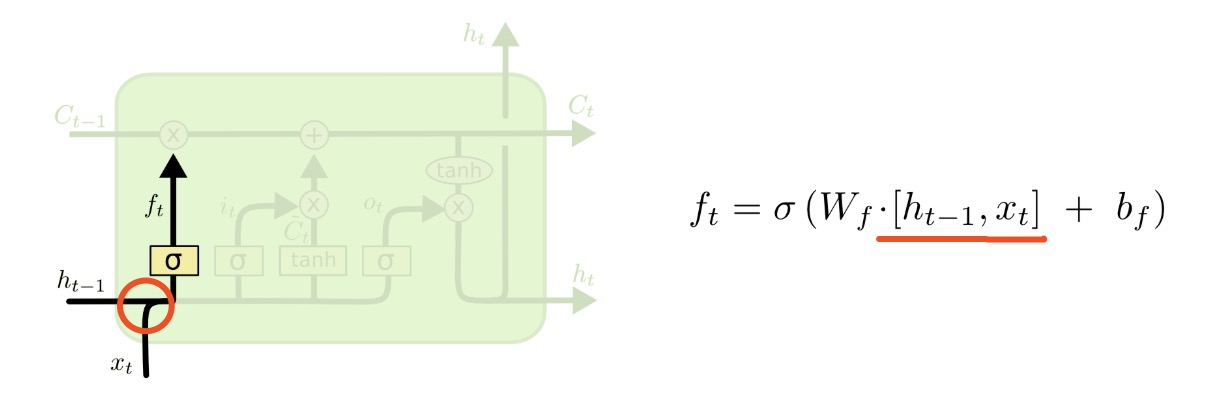
Think that we have a vector XY that is a concat of two other vectors (X and Y). Lets say that X has n x 1 as shape and Ymx1. Then, XY is (n+m) x 1. Lets also say that X has its weight matrix and Y too, and both matrixes map to the same dimension k. So Mx (X matrix) has k x n as shape and My has k x m. You can also say that there is a Mxy matrix that is a (concat?) of Mx and My (with shape k x (n+m)) and
Thanks for your reply! In the doc there is not sum operation in your expression, and the expression of forget gate indicate that xt and ht-1 should have same features, because ux and wh can be summed. There is still sth I don’t make clear.
Thanks for your reply! But in my opinion, we must guarantee the uniformity of features when do a concatenate operation rather than concatenate the features. So there is some questions I have not make sense of.
Essentially, the two methods are consistent, but just written in a different way. Suppose the LSTM’s hidden layer has 128 units, and the input layer has 300 units. In this case, ht-1 is a 128x1 vector, xt is a 300x1 vector, and ft has a dimension of 128x1. Wf is defined as [Whf, Wif]. Whf has a dimension of 128x128, Wif has a dimension of 128x300, and Wf has a dimension of 128x428.