@rvarm1 Glad for your reply!!
I am currently not able to provide my model defination since it’s a little mess and somehow internal. But I think the main issue is about may train loop, I provide my presudo code here hopefully your professional guys could know what caused this issue:
def train(rank, hyp, world_size):
cuda = torch.cuda.is_available()
if cuda:
torch.cuda.set_device(rank)
start_epoch = 0
best_mAP = 0.0
multi_scale_train = hyp.train.multi_scale
model_prefix = get_model_name(hyp)
if rank in [0, -1]:
if multi_scale_train:
print("Using multi scales training")
else:
print("train img size is {}".format(hyp.train.train_image_size))
if hyp.data.data_format == 'coco':
train_dataset = CocoDataset(
hyp, anno_file_type="train", img_size=hyp.train.train_image_size)
elif hyp.data.data_format == 'fn_anno':
train_dataset = FnAnnoDataset(
hyp, anno_file_type="train", img_size=hyp.train.train_image_size)
elif hyp.data.data_format == 'voc':
ValueError('{} to be supported'.format(hyp.data.data_format))
# this batch size is total which on all cards
bs = hyp.train.batch_size
total_batch_size = hyp.train.batch_size * world_size
epochs = hyp.train.epochs
model = BuildModel(hyp)
if hyp.train.sync_batch_norm and rank != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if rank == 0:
logger.info('Using SyncBatchNorm()')
logger.info('batch size: {} on single GPU, total batch size: {}'.format(
bs, total_batch_size))
if hyp.distributed:
if rank == 0:
logger.info(
'Enable DDP mode, using all gpus. rank: {}'.format(rank))
dist.init_process_group("nccl", rank=rank, world_size=world_size)
local_model = model.to(rank)
model = torch.nn.parallel.DistributedDataParallel(
local_model, device_ids=[rank], output_device=rank)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, rank=rank, shuffle=True)
# sampler_test = torch.utils.data.distributed.DistributedSampler(dataset_test)
train_dataloader = DataLoader(
train_dataset, sampler=train_sampler, batch_size=bs, num_workers=hyp.train.num_workers, pin_memory=True)
else:
local_model = model.to(rank)
train_dataloader = DataLoader(
train_dataset, batch_size=bs, num_workers=hyp.train.num_workers, shuffle=True, pin_memory=True)
if hyp.loss.loss_type == 'yolov4':
criterion = YoloV4Loss(anchors=hyp.model.anchors, strides=hyp.model.strides,
iou_threshold_loss=hyp['train']['iou_threshold_loss']).to(rank)
elif 'yolov5' in hyp.loss.loss_type: # for all yolov5 models
criterion = YoloV5Loss(hyp, anchors=hyp.model.anchors, strides=hyp.model.strides,
iou_threshold_loss=hyp['train']['iou_threshold_loss']).to(rank)
elif hyp.loss.loss_type == 'yolomask':
# to be done this loss
criterion = YoloV4Loss(anchors=hyp.model.anchors, strides=hyp.model.strides,
iou_threshold_loss=hyp['train']['iou_threshold_loss']).to(rank)
else:
ValueError('Unsupported model arch: {}'.format(hyp.model.arch))
# Settings for Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / total_batch_size), 1)
hyp.train.weight_decay *= total_batch_size * accumulate / nbs
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model.named_parameters():
v.requires_grad = True
if '.bias' in k:
pg2.append(v) # biases
elif '.weight' in k and '.bn' not in k:
pg1.append(v) # apply weight decay
else:
pg0.append(v) # all else
if hyp.train.optimizer == 'adam':
optimizer = optim.Adam(pg2, lr=hyp.train.lr_init, betas=(
hyp.train.momentum, 0.999)) # adjust beta1 to momentum
else:
optimizer = optim.SGD(pg2, lr=hyp.train.lr_init,
momentum=hyp.train.momentum, nesterov=True)
optimizer.add_param_group(
{'params': pg1, 'weight_decay': hyp.train.weight_decay})
logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' %
(len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
# Settings for lr strategy
# number of warmup iterations, max(3 epochs, 1k iterations)
nw = max(round(hyp.train.warmup_epochs * len(train_dataloader)), 1e3)
def lf(x): return ((1 + math.cos(x * math.pi / epochs)) / 2) * \
(1 - hyp.train.lrf) + hyp.train.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
scheduler.last_epoch = start_epoch - 1
scaler = amp.GradScaler(enabled=cuda)
last_weight = os.path.join(
hyp.weight_path, "{}_last.pt".format(model_prefix))
if os.path.exists(last_weight) and hyp.resume:
if rank in [0, -1]:
print('resume from last pth: ', last_weight)
chkpt = torch.load(last_weight)
# using local model to load state_dict, avoid module issue
local_model.load_state_dict(chkpt['model'])
start_epoch = chkpt["epoch"] + 1
if chkpt["optimizer"] is not None:
optimizer.load_state_dict(chkpt["optimizer"])
best_mAP = chkpt["best_mAP"]
del chkpt
else:
if rank in [0, -1]:
print('last pth not found or not resume, skip resume...')
writer = SummaryWriter(logdir=hyp.log_path + "/event")
if rank == 0:
logger.info("Training start,img size is: {:d}, batchsize is: {:d}, work number is {:d}".format(
hyp.train.train_image_size, hyp.train.batch_size, hyp['train']['num_workers']))
logger.info("Train datasets number is : {}".format(len(train_dataset)))
logger.info('*'*20 + ' start training ' + '*'*20)
if hyp.fp16:
model, optimizer = amp.initialize(
model, optimizer, opt_level="O1", verbosity=0)
# hyp not allowed to change after all set
hyp.freeze()
for epoch in range(start_epoch, epochs):
start = time.time()
model.train()
...
optimizer.zero_grad()
for i, (imgs, label_sbbox, label_mbbox, label_lbbox,
sbboxes, mbboxes, lbboxes) in enumerate(train_dataloader):
...
with amp.autocast(enabled=cuda):
p, p_d = model(imgs)
loss, loss_ciou, loss_conf, loss_cls = criterion(
p, p_d, label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes)
# Backward
if hyp.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
# scaler.scale(loss).backward()
else:
loss.backward()
# Accumulate gradient for x batches before optimizing
if ni % accumulate == 0:
# print('accumulate: ', accumulate)
optimizer.step()
optimizer.zero_grad()
torch.cuda.empty_cache()
def main(hyp):
get_gpu_prop(True)
world_size = get_gpu_devices_count()
print('world size: ', world_size)
if hyp.distributed:
print('Start distributed training...')
mp.spawn(train,
args=(hyp, world_size,),
nprocs=world_size,
join=True)
else:
print('Start single GPU training...')
train(0, hyp, world_size)
if __name__ == "__main__":
parser = argparse.ArgumentParser('YoloV5 written by Me')
parser.add_argument('-c', '--config', type=str, default='configs/tiiii/v4_mbv3.yml',
help='config file path to train.')
parser.add_argument("--resume", action='store_true')
parser.add_argument("--pretrain_path", type=str, default="weights/mobilenetv3.pth",
help="weight file path")
parser.add_argument("--accumulate", type=int, default=2,
help="batches to accumulate before optimizing")
parser.add_argument("--fp16", type=bool, default=False,
help="whither to use fp16 precision")
parser.add_argument("opts", default=None,
nargs=argparse.REMAINDER, help="rest options")
opt = parser.parse_args()
cfg.merge_from_file(opt.config)
cfg.merge_from_list(opt.opts)
hyp = cfg
os.makedirs(hyp.weight_path, exist_ok=True)
os.makedirs(hyp.log_path, exist_ok=True)
if get_gpu_devices_count() > 1:
hyp.distributed = True
# Automatic mixed precision
hyp.amp = False
if torch.cuda.is_available() and torch.__version__ >= "1.6.0":
capability = torch.cuda.get_device_capability()[0]
if capability >= 7: # 7 refers to RTX series GPUs, e.g. 2080Ti, 2080, Titan RTX
hyp.amp = True
print("Automatic mixed precision (AMP) is enabled!")
main(hyp)
The mainly issue is that: training from scratch with 8 GPUs, it averages perfectly on memory, but when resume which only difference is the load weight part, got GPU imbalance and casuse first GPU OOM.
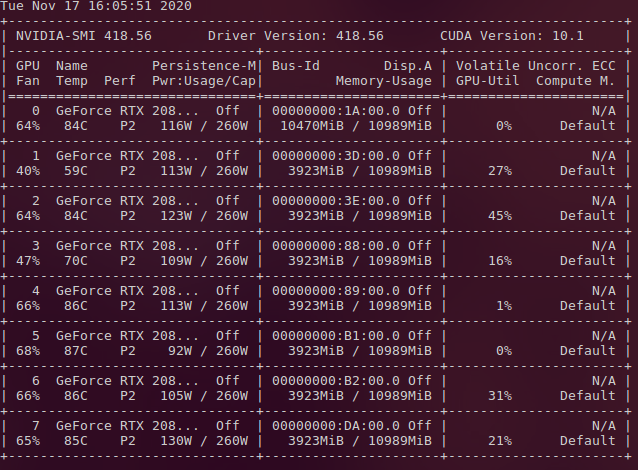
As you can see, I donn’t how to solve this issue now.