Hello everyone.
I am using pytorch’s QAT to compress ViT model. The model does shrink to a significant extent however the training slows down. A single without the QAT takes 149.9 secs and when trained with the same hyper-parameters (QAT on) takes 273 secs.
This shouldn’t happen as the only thing that changed was model becoming quantised. The memory shrinked 3.89 x which was expected. Can someone help me figure out why this is happening?
I’d suggest profiling the two runs and seeing where the additional time is spent.
We have two tutorials on using our inbuilt profiling tools:
-
Profiling your PyTorch Module — PyTorch Tutorials 1.12.0+cu102 documentation
-
PyTorch Profiler With TensorBoard — PyTorch Tutorials 1.12.0+cu102 documentation
There’s also the API docs for the profiler here: torch.profiler — PyTorch 1.12 documentation
Okay. I’ll do this and update the thread, thank you!
Hey. I ran the profiler on my model. I find it’s interpretation difficult although I do observe a few things.
First. every process that occurs during the forward pass of my non quantised model gets slower after quantisation. By using profiler.record_function I observe the forward VIT pass to slow down over 4 times. Every other process witnessed some increase in computational time.
Second, I also observed new processes associated with the quantisation
(things like aten::fused_moving_avg_obs_fake_quant, aten::fake_quantize_per_channel_affine_cachemask)
I can see why the extra time costs due to both of the above mentioned points lead to slowing down of the model.
A screenshot of the profiling is attached below.I still can’t figure out what’s going wrong though…
Screenshot one shows the non-quantised model and image 2 shows the quantised model profile.
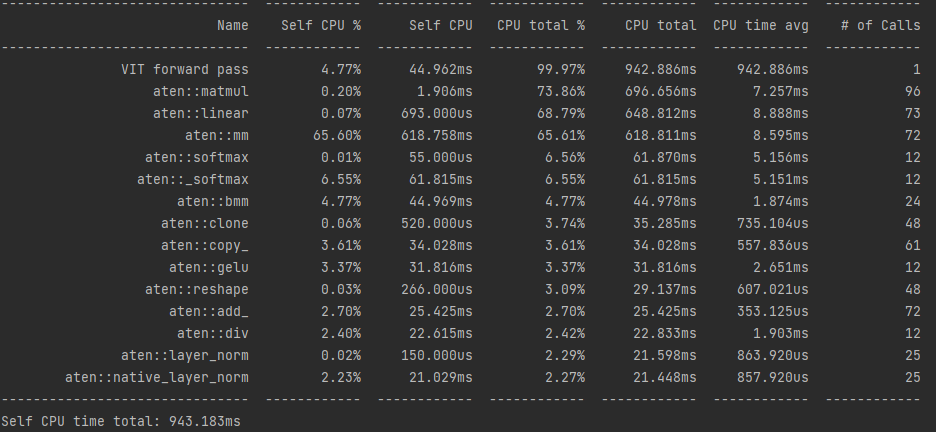
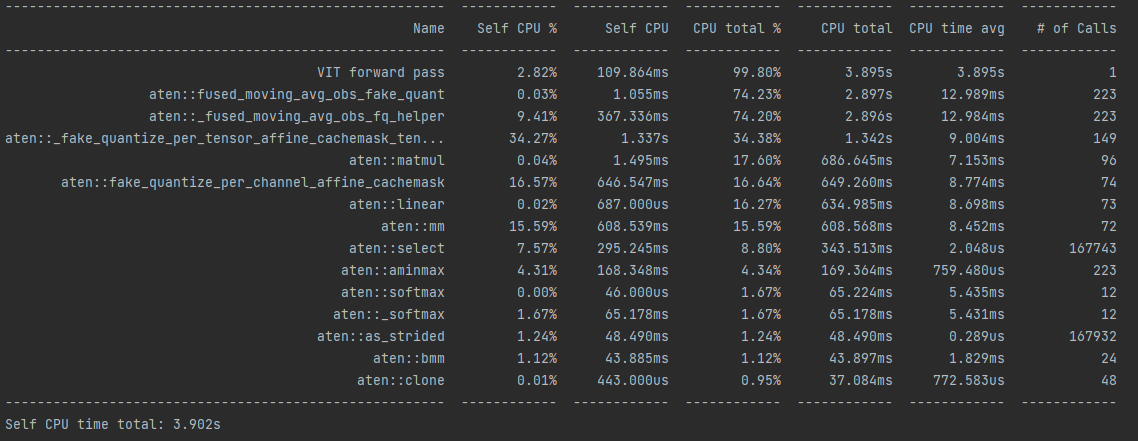
@smth I was still unable to solve this issue, can you look at the above screenshots and help me out? Thank you in advance.
have you tried using: https://github.com/pytorch/pytorch/blob/master/torch/ao/quantization/qconfig.py#L215
No i haven’t. Can you explain the implementation details a bit? How does this config lead to performance benefits? Should the code look like this →
from torch.quantization.qconfig import QConfig
from torch.quantization.fake_quantize import default_fused_act_fake_quant,default_fused_wt_fake_quant
Model.train()
Model = Model.cpu()
Model.qconfig = QConfig(activation=default_fused_act_fake_quant, weight=default_fused_wt_fake_quant)
torch.quantization.prepare_qat(Model,inplace=True)
@jerryzh168 hai, In the quantization aware trainging , the activation just to be the 0-255? i want to do -128 to 127 , do you help me ?
yeah you can set it explicitly, for example: pytorch/fake_quantize.py at master · pytorch/pytorch · GitHub
this qconfig uses the fused fake quant module, which implements observation/fake quantization in the same operator and in C++, so it has a better perf
the same i have a error .i used the this to set the activation.
Uploading: 1660180760975.png…
Uploading: 16453816e1b651551c17556ac1deb04.png…
the error is … when i used troch.jit.trace()

this question i get it , i have another questions , bias 32int, i want to set it 8int , i need to do ?
oh, this is only for weight, not for activation, for activation you need to use pytorch/fake_quantize.py at master · pytorch/pytorch · GitHub
right now bias is in fp32 actually, but it will get quantized to int32 in the operators.
for int8 bias, we do not have any operator that supports this right now, are you running the model in some custom hardware? If so, we do have an api that produce a “reference quantized model” that will support this use case. Here is the api: pytorch/backend_config.py at master · pytorch/pytorch · GitHub and design doc: rfcs/RFC-0019-Extending-PyTorch-Quantization-to-Custom-Backends.md at master · pytorch/rfcs · GitHub, this is still in early stage of development though, maybe we’ll announce the prototype support some time later this year
i dont use fx ,so Can i use the API?
which api are you talking about? if you are talking about reference quantized model, we do plan to implement this in eager mode quantization as well, but it might take some time
i dont use fx , Can i use the backend_config.py (BackendConfig:) to set the bias type
if i have to change bias type = qint8, where i need to see and change? i dont get it …
you write qint32 by c and wo dont change it ? i dont understand, if you write by python ,i can chagne